
VGGT: Visual Geometry Grounded Transformer

VGGT: Visual Geometry Grounded Transformer
VGGT(CVPR'25):基于预训练模型抽取特征,通过网络预测3D场景的多种信息。
代码仓库
注:笔者对3D场景重建相关领域工作并不熟悉,仅记录自己的理解。
动机
本文希望实现一个能够端到端从单图或多图预测多种3D场景信息的模型,输出结果包括相机参数、点云图、深度图和3D点轨迹。
方法
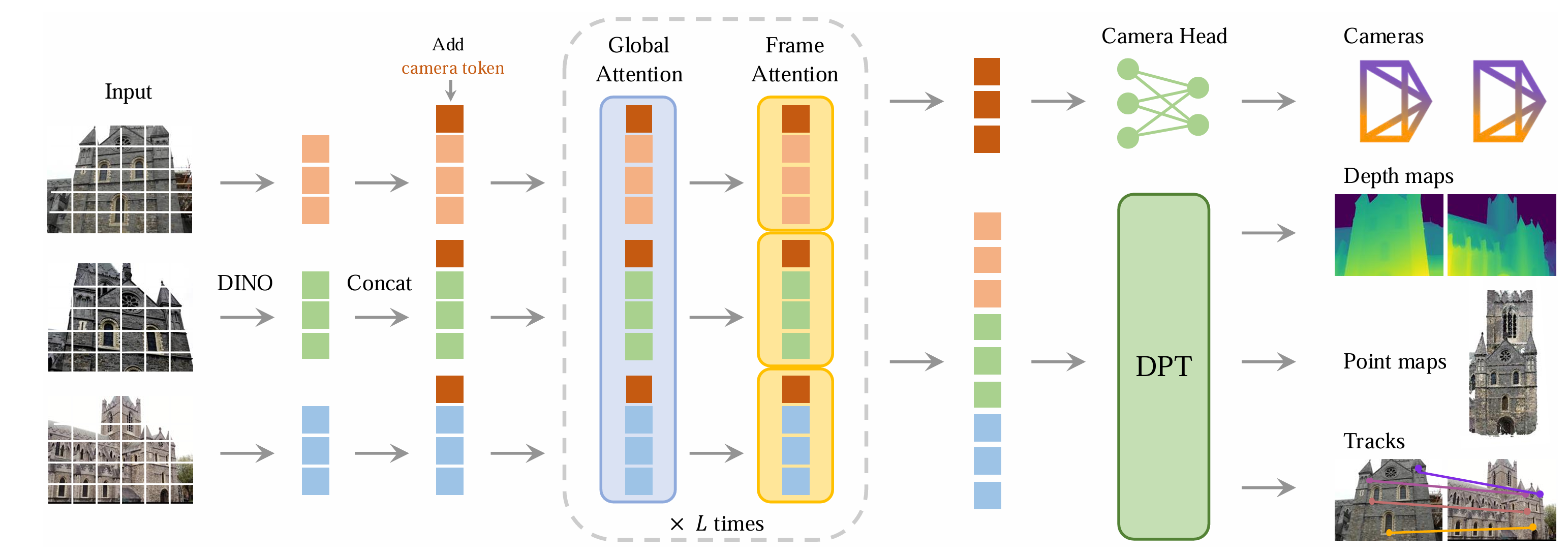
本文设定的场景为通过一个图片序列预测3D场景信息。该图片序列理论上是可以任意顺序输入,不过实际实现中是以第一帧为参考。
对于每帧图像,通过DINO提取特征,获得对应每帧图像的token序列。随后再在帧token序列上添加一个相机token和四个register token,作为可学习参数。
随后将组合的特征送入一个改装的自注意力模块,交替进行全局自注意力和帧内自注意力。输出的特征向量分解为相机token及图像特征,送入相应的后续网络完成后续任务。
训练方面似乎更多参照了已有工作,笔者对相关领域不太了解,详细内容请见原文。
实验

具有优秀的重建结果,在多种任务上达到了SOTA水平,详见原文。
总结
按照笔者的理解,本文的突出贡献主要在于完成了一个端到端的3D场景重建模型,能够输出多种信息。从技术角度理解,是利用自监督预训练模型提取的特征构建网络预测目标信息。
相关新闻

2026/7/18 17:21:43
微信小程序使用地图map 实现定位和实时绘画轨迹

2026/7/22 21:38:31
嵌入式入门,基于keil5用stm32寄存器和标准库实现LED流水灯

2026/7/26 23:02:02
小人鱼的数学题 - Li

2026/7/27 22:47:48
Prompt设计实战:提升AI交互效果的4种核心方法

2026/7/27 22:46:28
2026 年新发布:回民诚信的静电地板哪家好定制厂家哪个好,机房选地面别瞎踩坑,这玩意儿竟能帮你省半年运维费?-亚豪防静电地板 - 企业官方推荐【认证】

2026/7/27 22:46:28
2026实力之选:深圳纸罐厂家-广东多普包装技术有限公司,专业的天地盖纸罐、平口纸罐、牛皮纸罐与食品复合罐源头企业 - 卓企推荐

2026/7/27 22:46:28
Audio Slicer智能音频分割工具:基于静音检测的自动化音频处理解决方案

2026/7/27 22:45:10
Agent 的“大脑-手“解耦架构:当推理层和工具执行层各自独立演进

2026/7/27 22:44:31
多智能体协同AI图像翻译系统:跨境电商图片本地化解决方案

2026/7/27 0:16:44
技术焦虑下的业务聚焦:构建可持续的技术竞争力
,免费生成专属「提分热力图」与瓶颈突破路线图)
2026/7/27 8:51:27
仅限本周开放|GMAT AI备考效能评估工具(含ETS官方题库行为轨迹比对模块),免费生成专属「提分热力图」与瓶颈突破路线图

2026/7/27 2:05:53
AI时代SEO新标配:Schema结构化数据与llms.txt实战指南

2026/7/27 0:01:04
基于YOLOv13的建筑病害智能检测系统开发与实践

2026/7/27 0:01:47
从经典QSAR到AI药物设计:分子描述符的演进与应用

2026/7/27 0:01:47
2026年7月江苏省无锡市电信500M单宽带怎么安装? - 找卡家园
![[C++]内存管理:串顺序存储的内存回收](http://pic.xiahunao.cn/yaotu/[C++]内存管理:串顺序存储的内存回收)
2026/7/27 13:53:17
[C++]内存管理:串顺序存储的内存回收
:ArkUI 首页仪表盘搭建)
2026/7/27 13:53:19
足球口袋教练 HarmonyOS 离线应用实战(03/20):ArkUI 首页仪表盘搭建

2026/7/26 19:42:19