作业①:
要求:
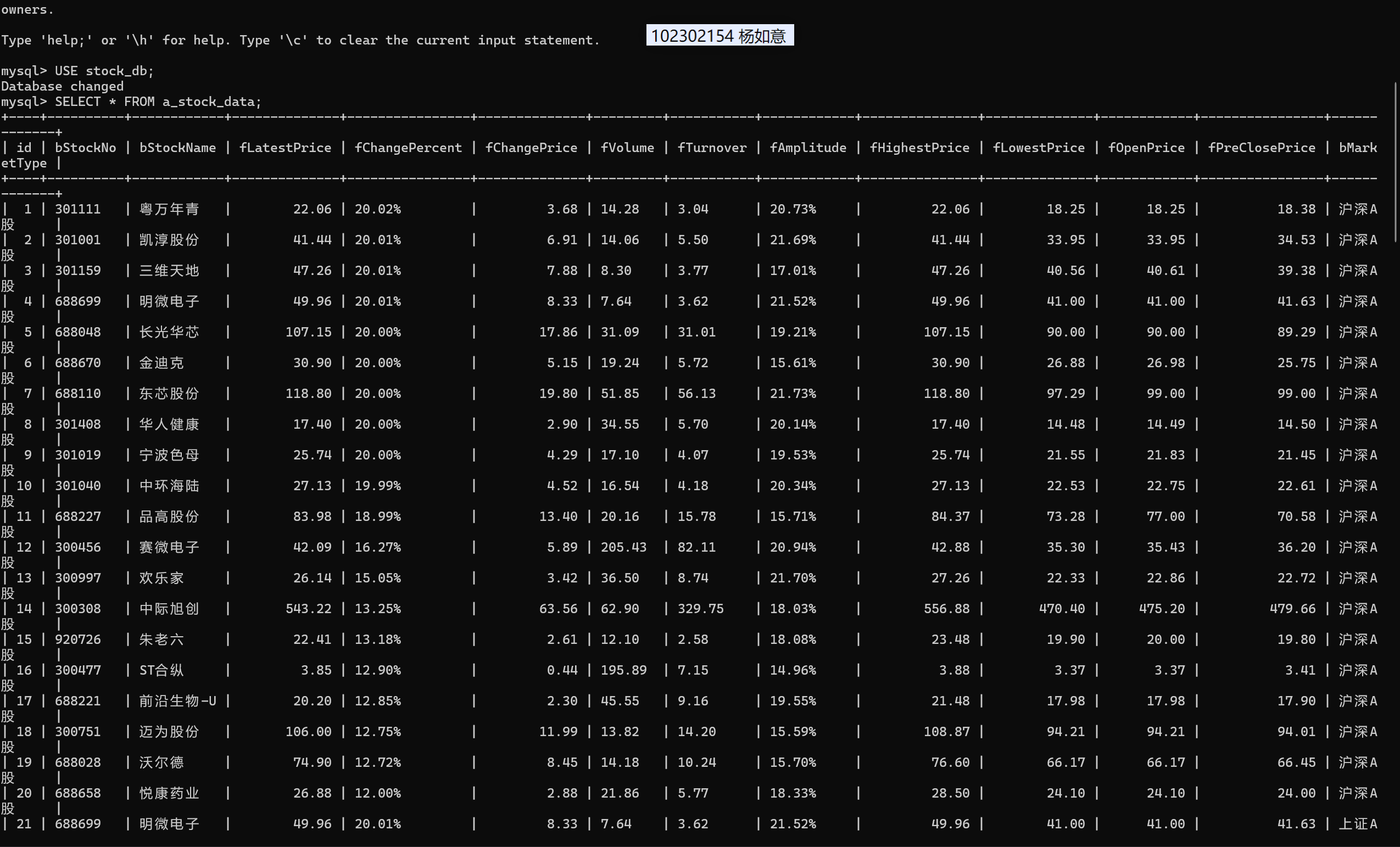
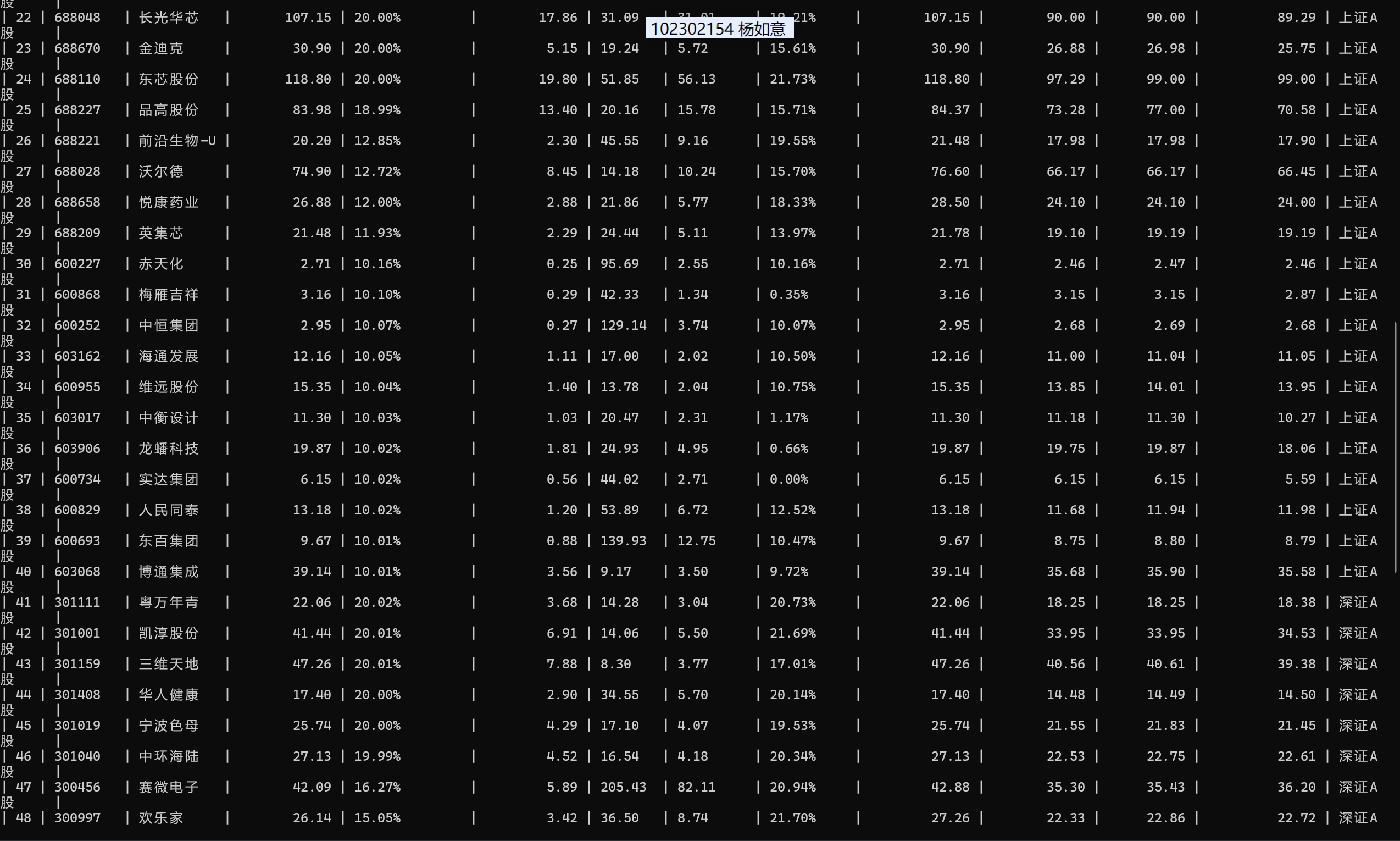
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
点击查看代码
class StockDataCrawler:"""东方财富网股票数据爬虫"""def __init__(self, db_host, db_user, db_pass, db_schema):self.browser = self._init_browser()self.wait = WebDriverWait(self.browser, 30)self.db_connection = pymysql.connect(host=db_host,user=db_user,password=db_pass,database=db_schema,charset='utf8mb4')self.db_cursor = self.db_connection.cursor()self._init_database()def _init_browser(self):chrome_opts = webdriver.ChromeOptions()chrome_opts.add_argument("--start-maximized")chrome_opts.add_argument("--lang=zh-CN")chrome_opts.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36")driver = webdriver.Chrome(options=chrome_opts)driver.set_page_load_timeout(40)return driverdef _init_database(self):self.db_cursor.execute("DROP TABLE IF EXISTS a_stock_data;")create_table_sql = """CREATE TABLE a_stock_data (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '序号',bStockNo VARCHAR(20) NOT NULL COMMENT '股票代码',bStockName VARCHAR(50) NOT NULL COMMENT '股票名称',fLatestPrice DECIMAL(10,2) NOT NULL COMMENT '最新报价',fChangePercent VARCHAR(10) COMMENT '涨跌幅',fChangePrice DECIMAL(10,2) COMMENT '涨跌额',fVolume VARCHAR(20) COMMENT '成交量',fTurnover VARCHAR(20) COMMENT '成交额',fAmplitude VARCHAR(10) COMMENT '振幅',fHighestPrice DECIMAL(10,2) COMMENT '最高',fLowestPrice DECIMAL(10,2) COMMENT '最低',fOpenPrice DECIMAL(10,2) COMMENT '今开',fPreClosePrice DECIMAL(10,2) COMMENT '昨收',bMarketType VARCHAR(20) NOT NULL COMMENT '市场类型',UNIQUE KEY uk_stock_market (bStockNo, bMarketType)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='A股股票数据';"""self.db_cursor.execute(create_table_sql)self.db_connection.commit()print("=" * 50)print(" 数据表初始化完成")print("=" * 50)def _is_row_valid(self, row_content):filter_keywords = ['加自选', '相关链接', '资讯']for kw in filter_keywords:if kw in row_content:return Falsereturn bool(re.search(r'\b\d{6}\b', row_content))def _clean_numeric(self, num_str):if not num_str:return Nonecleaned = re.sub(r'[^\d\.\-\+\%]', '', str(num_str))return cleaned if cleaned not in ['', '-', '--'] else Nonedef _safe_float_convert(self, num_str):cleaned_num = self._clean_numeric(num_str)if not cleaned_num:return Nonetry:if '%' in cleaned_num:return float(cleaned_num.replace('%', ''))return float(cleaned_num)except:print(f"数值转换失败: 原始值[{num_str}] 清洗后[{cleaned_num}]")return Nonedef fetch_stock_data(self, target_url, market_category, max_count=20):# 标题分隔线print("\n" + "=" * 60)print(f"正在抓取 [{market_category}] 数据 (最多 {max_count} 条)")print("-" * 60)try:self.browser.get(target_url)stock_table = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".quotetable tbody")))time.sleep(3)rows = stock_table.find_elements(By.TAG_NAME, "tr")print(f"发现 {len(rows)} 行原始数据")print("-" * 40)valid_records = []success_count = 0for idx, row in enumerate(rows):if success_count >= max_count:breaktry:row_text = row.text.strip()if not row_text:continueif not self._is_row_valid(row_text):continuecolumns = row.find_elements(By.TAG_NAME, "td")if len(columns) < 15:continuestock_code = columns[1].text.strip()stock_name = columns[2].text.strip()latest_price = Nonefor col_idx in [3, 4, 5]:if col_idx < len(columns):latest_price = self._safe_float_convert(columns[col_idx].text.strip())if latest_price is not None:breakif latest_price is None:continueprice_col_pos = Nonefor i in [3, 4, 5]:if i < len(columns) and self._safe_float_convert(columns[i].text.strip()) == latest_price:price_col_pos = ibreakchange_pct = self._clean_numeric(columns[price_col_pos + 1].text.strip()) if (price_col_pos + 1) < len(columns) else Nonechange_val = self._safe_float_convert(columns[price_col_pos + 2].text.strip()) if (price_col_pos + 2) < len(columns) else Nonevolume = self._clean_numeric(columns[price_col_pos + 3].text.strip()) if (price_col_pos + 3) < len(columns) else Noneturnover = self._clean_numeric(columns[price_col_pos + 4].text.strip()) if (price_col_pos + 4) < len(columns) else Noneamplitude = self._clean_numeric(columns[price_col_pos + 5].text.strip()) if (price_col_pos + 5) < len(columns) else Nonehighest = self._safe_float_convert(columns[price_col_pos + 6].text.strip()) if (price_col_pos + 6) < len(columns) else Nonelowest = self._safe_float_convert(columns[price_col_pos + 7].text.strip()) if (price_col_pos + 7) < len(columns) else Noneopen_val = self._safe_float_convert(columns[price_col_pos + 8].text.strip()) if (price_col_pos + 8) < len(columns) else Nonepre_close = self._safe_float_convert(columns[price_col_pos + 9].text.strip()) if (price_col_pos + 9) < len(columns) else Noneif not (stock_code and stock_name):continuevalid_records.append((stock_code, stock_name, latest_price, change_pct, change_val,volume, turnover, amplitude, highest, lowest,open_val, pre_close, market_category))success_count += 1# 进度条样式progress = int((success_count / max_count) * 20)progress_bar = "[" + "■" * progress + " " * (20 - progress) + "]"print(f"{success_count:2d}/{max_count} {progress_bar} {stock_code} {stock_name.ljust(8)} 价格: {latest_price:.2f}")except NoSuchElementException:continueexcept Exception as e:print(f"第{idx + 1}行处理错误: {str(e)}")continueif valid_records:insert_sql = """INSERT INTO a_stock_data (bStockNo, bStockName, fLatestPrice, fChangePercent, fChangePrice,fVolume, fTurnover, fAmplitude, fHighestPrice, fLowestPrice,fOpenPrice, fPreClosePrice, bMarketType)VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)ON DUPLICATE KEY UPDATEfLatestPrice = VALUES(fLatestPrice),fChangePercent = VALUES(fChangePercent),fChangePrice = VALUES(fChangePrice)"""self.db_cursor.executemany(insert_sql, valid_records)self.db_connection.commit()print("\n" + "-" * 40)print(f" [{market_category}] 抓取完成 | 有效数据: {len(valid_records)} 条")else:print("\n" + "-" * 40)print(f"[{market_category}] 未获取到有效数据")except TimeoutException:print(f"[{market_category}] 页面加载超时")except Exception as e:print(f"[{market_category}] 抓取异常: {str(e)}")def shutdown(self):try:self.db_cursor.close()self.db_connection.close()except Exception as e:print(f"数据库关闭错误: {str(e)}")self.browser.quit()print("\n" + "=" * 60)print("爬虫已结束,所有资源已释放")print("=" * 60)def run_crawler():db_settings = {'host': 'localhost','user': 'root','password': '123456','schema': 'stock_db'}fetch_limit = 20market_configs = {"沪深A股": "http://quote.eastmoney.com/center/gridlist.html#hs_a_board","上证A股": "http://quote.eastmoney.com/center/gridlist.html#sh_a_board","深证A股": "http://quote.eastmoney.com/center/gridlist.html#sz_a_board"}crawler = StockDataCrawler(db_settings['host'],db_settings['user'],db_settings['password'],db_settings['schema'])try:for market_name, url in market_configs.items():crawler.fetch_stock_data(url, market_name, fetch_limit)time.sleep(5)print("\n" + "=" * 50)print("抓取结果统计")print("-" * 30)crawler.db_cursor.execute("""SELECT bMarketType, COUNT(*) FROM a_stock_data GROUP BY bMarketType""")stats = crawler.db_cursor.fetchall()total = 0for market, count in stats:print(f"{market.ljust(6)} | {count} 条数据")total += countprint("-" * 30)print(f"总计 | {total} 条数据")finally:crawler.shutdown()if __name__ == "__main__":run_crawler()
心得体会:
爬取三个 A 股板块时,最关键的是处理等待逻辑 —— 股票数据是动态加载的,直接查找元素肯定超时。我用了 WebDriverWait 显式等待,直到元素可点击或可见再操作,再也没遇到超时报错。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
点击查看代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
import pymysql
import time
import re # 导入正则模块(原代码遗漏)# ========== 全局配置 ==========
DB_CONFIG = {'host': 'localhost','port': 3306,'user': 'root','password': '123456','database': 'mooc_db','charset': 'utf8mb4'
}
USERNAME = "13023816281"
PASSWORD = "YRY200513yry"
COURSE_LIST = ["https://www.icourse163.org/course/ZJU-1472847200","https://www.icourse163.org/course/NJU-1001573001?outVendor=zw_mooc_pcsybzkcph_","https://www.icourse163.org/course/NKU-1205696807?outVendor=zw_mooc_pcsybzkcph_",]def init_browser():from selenium.webdriver.chrome.service import Service # 确保导入 Serviceoptions = Options()options.add_experimental_option("excludeSwitches", ["enable-logging"])options.add_argument('--start-maximized')driver_path = r"E:\ChromeDriver\chromedriver.exe" service = Service(executable_path=driver_path)driver = webdriver.Chrome(service=service,options=options)driver.implicitly_wait(10)return driverdef setup_database():try:# 连接数据库conn = pymysql.connect(**DB_CONFIG)cursor = conn.cursor()print("数据库连接成功!")# 创建课程信息表(如果不存在)create_table_sql = '''CREATE TABLE IF NOT EXISTS course_info (id INT AUTO_INCREMENT PRIMARY KEY,course_id VARCHAR(20) NOT NULL,course_name VARCHAR(100) NOT NULL,university VARCHAR(50) NOT NULL,instructor VARCHAR(50) NOT NULL,team_members VARCHAR(200) NOT NULL,student_count VARCHAR(20) NOT NULL,schedule VARCHAR(50) NOT NULL,description TEXT NOT NULL,UNIQUE KEY unique_course_id (course_id)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;'''cursor.execute(create_table_sql)conn.commit()return conn, cursorexcept Exception as e:print(f"数据库初始化失败:{e}")exit(1)# ========== 登录相关函数(修复中国大学MOOC登录流程) ==========
def click_login(driver):"""点击中国大学MOOC的登录按钮(适配页面结构)"""login_xpaths = ["//a[@class='u-btn u-btn-primary f-fr j-login']", # 顶部登录按钮"//a[contains(text(), '登录') and @data-action='login']","//button[contains(text(), '登录')]"]for xpath in login_xpaths:try:login_btn = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, xpath)))login_btn.click()print(" 点击登录按钮成功")time.sleep(2)return Trueexcept:continueprint(" 未找到可点击的登录按钮")return Falsedef fill_login_form(driver, username, password):"""填充登录表单(适配中国大学MOOC的iframe登录框)"""try:# 切换到登录iframe(中国大学MOOC登录框在iframe中)iframe = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//iframe[contains(@src, 'login')]")))driver.switch_to.frame(iframe)print("切换到登录iframe成功")# 输入手机号(适配手机号输入框)phone_input = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//input[@name='phone' or @placeholder='手机号']")))phone_input.clear()phone_input.send_keys(username)print(" 输入用户名成功")# 输入密码pwd_input = driver.find_element(By.XPATH, "//input[@name='password' or @placeholder='密码']")pwd_input.clear()pwd_input.send_keys(password)print("输入密码成功")driver.switch_to.default_content() # 切回主页面return Trueexcept Exception as e:print(f"填充登录表单失败:{e}")driver.switch_to.default_content()return Falsedef submit_login(driver):"""提交登录表单"""try:# 重新切换到iframe提交iframe = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//iframe[contains(@src, 'login')]")))driver.switch_to.frame(iframe)# 点击登录提交按钮submit_btn = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, "//button[contains(text(), '登录') and @type='submit']")))submit_btn.click()print("提交登录成功")driver.switch_to.default_content()time.sleep(3) # 等待登录跳转return Trueexcept Exception as e:print(f"提交登录失败:{e}")driver.switch_to.default_content()return Falsedef check_login(driver):"""检查登录是否成功(通过是否显示用户名判断)"""try:# 登录成功后,顶部会显示用户名/头像WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//a[@class='u-btn u-btn-link f-fr j-user']")))print(" 登录成功!")return Trueexcept:print("登录失败(未检测到用户信息)")return Falsedef login(driver, username, password):"""登录主流程"""print("===== 开始登录中国大学MOOC =====")driver.get("https://www.icourse163.org/") # 打开MOOC首页time.sleep(2)if not click_login(driver):return Falseif not fill_login_form(driver, username, password):return Falseif not submit_login(driver):return Falsereturn check_login(driver)# ========== 课程爬取函数(修复选择器适配MOOC页面) ==========
def get_course_info(driver, url, course_id):"""爬取单门课程信息"""print(f"\n===== 爬取课程:{url} =====")info = {"course_id": course_id,"course_name": f"课程{course_id}","university": "未知学校","instructor": "未知教师","team_members": "未知教师","student_count": "0","schedule": "未知","description": "暂无简介"}try:driver.get(url)time.sleep(3) # 1. 课程名称try:# 修正双引号冲突:将 XPath 内的双引号改为单引号,或外层用单引号title = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//*[@id='g-body']/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[1]"))).text.strip()info['course_name'] = title if title else info['course_name']except:pass# 2. 学校名称try:school = driver.find_element(By.XPATH, "//*[@id='j-teacher']/div/a/img").text.strip()info['university'] = school if school else info['university']except:pass# 3. 主讲教师try:instructor = driver.find_element(By.XPATH, "//*[@id='j-teacher']/div/div/div[2]/div/div/div").text.strip()info['instructor'] = instructor if instructor else info['instructor']except:pass# 4. 团队成员team_members = []try:# 找到课程团队区域team_area = driver.find_element(By.XPATH, "//div[contains(@class, 'm-teacher-list')]")member_elems = team_area.find_elements(By.XPATH, "//a[contains(@class, 'u-teacher-link')]")team_members = [elem.text.strip() for elem in member_elems if elem.text.strip()]# 去重并排除主讲教师team_members = list(set(team_members) - {info['instructor']})info['team_members'] = ', '.join(team_members) if team_members else info['instructor']except:info['team_members'] = info['instructor']# 5. 参与人数try:count_text = driver.find_element(By.XPATH,"//*[@id='course-enroll-info']/div/div[1]/div[4]/span[2]").textmatch = re.search(r"(\d+(?:,\d+)?)", count_text)if match:info['student_count'] = match.group(1).replace(',', '') # 去除千位分隔符except:pass# 6. 课程进度try:schedule = driver.find_element(By.XPATH, "//*[@id='course-enroll-info']/div/div[1]/div[4]").text.strip()info['schedule'] = schedule if schedule else info['schedule']except:pass# 7. 课程简介try:# 点击"展开更多"(如果有)try:more_btn = driver.find_element(By.XPATH, "//*[@id='content-section']/div[4]")driver.execute_script("arguments[0].click();", more_btn)time.sleep(1)except:pass# 提取简介文本intro = driver.find_element(By.XPATH,"//*[@id='content-section']/div[4]").text.strip()info['description'] = intro[:500] + "..." if len(intro) > 500 else introexcept:pass# 打印爬取结果print(f" 课程名称:{info['course_name']}")print(f" 学校:{info['university']}")print(f" 主讲教师:{info['instructor']}")print(f" 团队成员:{info['team_members']}")print(f" 参与人数:{info['student_count']}")print(f" 进度:{info['schedule']}")print(f" 简介:{info['description'][:50]}...")except Exception as e:print(f" 爬取课程失败:{e}")return infodef save_course(conn, cursor, data):"""保存课程信息到数据库"""try:sql = '''INSERT INTO course_info (course_id, course_name, university, instructor, team_members, student_count, schedule, description)VALUES (%s, %s, %s, %s, %s, %s, %s, %s)ON DUPLICATE KEY UPDATE # 存在则更新(避免重复)course_name=%s, university=%s, instructor=%s, team_members=%s,student_count=%s, schedule=%s, description=%s'''# 执行SQL(参数重复是因为ON DUPLICATE KEY UPDATE需要)cursor.execute(sql, (data['course_id'], data['course_name'], data['university'], data['instructor'],data['team_members'], data['student_count'], data['schedule'], data['description'],# 更新用的参数data['course_name'], data['university'], data['instructor'], data['team_members'],data['student_count'], data['schedule'], data['description']))conn.commit()print(f"已保存课程到数据库:{data['course_name']}\n")except Exception as e:print(f"保存数据库失败:{e}")conn.rollback()def display_data(cursor):"""显示数据库中的课程信息"""try:cursor.execute("SELECT * FROM course_info")records = cursor.fetchall()print("\n" + "=" * 180)print(" 数据库中的MOOC课程信息:")print("=" * 180)print(f"{'ID':<3} {'课程号':<8} {'课程名称':<30} {'学校':<15} {'主讲教师':<12} "f"{'团队成员':<20} {'参与人数':<10} {'进度':<15} {'简介':<30}")print("-" * 180)for record in records:description = record[8][:30] + "..." if record[8] and len(record[8]) > 30 else record[8]print(f"{record[0]:<3} {record[1]:<8} {record[2]:<30} {record[3]:<15} {record[4]:<12} "f"{record[5]:<20} {record[6]:<10} {record[7]:<15} {description:<30}")print(f"\n总计:{len(records)} 门课程")except Exception as e:print(f" 读取数据库失败:{e}")# ========== 主函数 ==========
if __name__ == "__main__":print("=" * 50)print("中国大学MOOC课程爬虫 v1.0")print("=" * 50)# 1. 初始化数据库conn, cursor = setup_database()# 2. 清空历史数据(可选,注释掉则保留历史)try:cursor.execute("DELETE FROM course_info")conn.commit()print(" 已清空历史课程数据")except Exception as e:print(f" 清空历史数据失败:{e}")# 3. 初始化浏览器driver = init_browser()# 4. 登录login_success = login(driver, USERNAME, PASSWORD)if not login_success:print(" 登录失败,尝试爬取公开课程...")# 5. 爬取课程print(f"\n===== 开始爬取 {len(COURSE_LIST)} 门课程 =====")for i, url in enumerate(COURSE_LIST, 1):course_id = f"C{i:03d}" # 生成课程号:C001, C002...course_data = get_course_info(driver, url, course_id)save_course(conn, cursor, course_data)time.sleep(2) # 爬取间隔,避免反爬# 6. 显示结果display_data(cursor)# 7. 资源释放driver.quit()cursor.close()conn.close()print("\n" + "=" * 50)print(" 爬虫执行完成!")print("=" * 50)
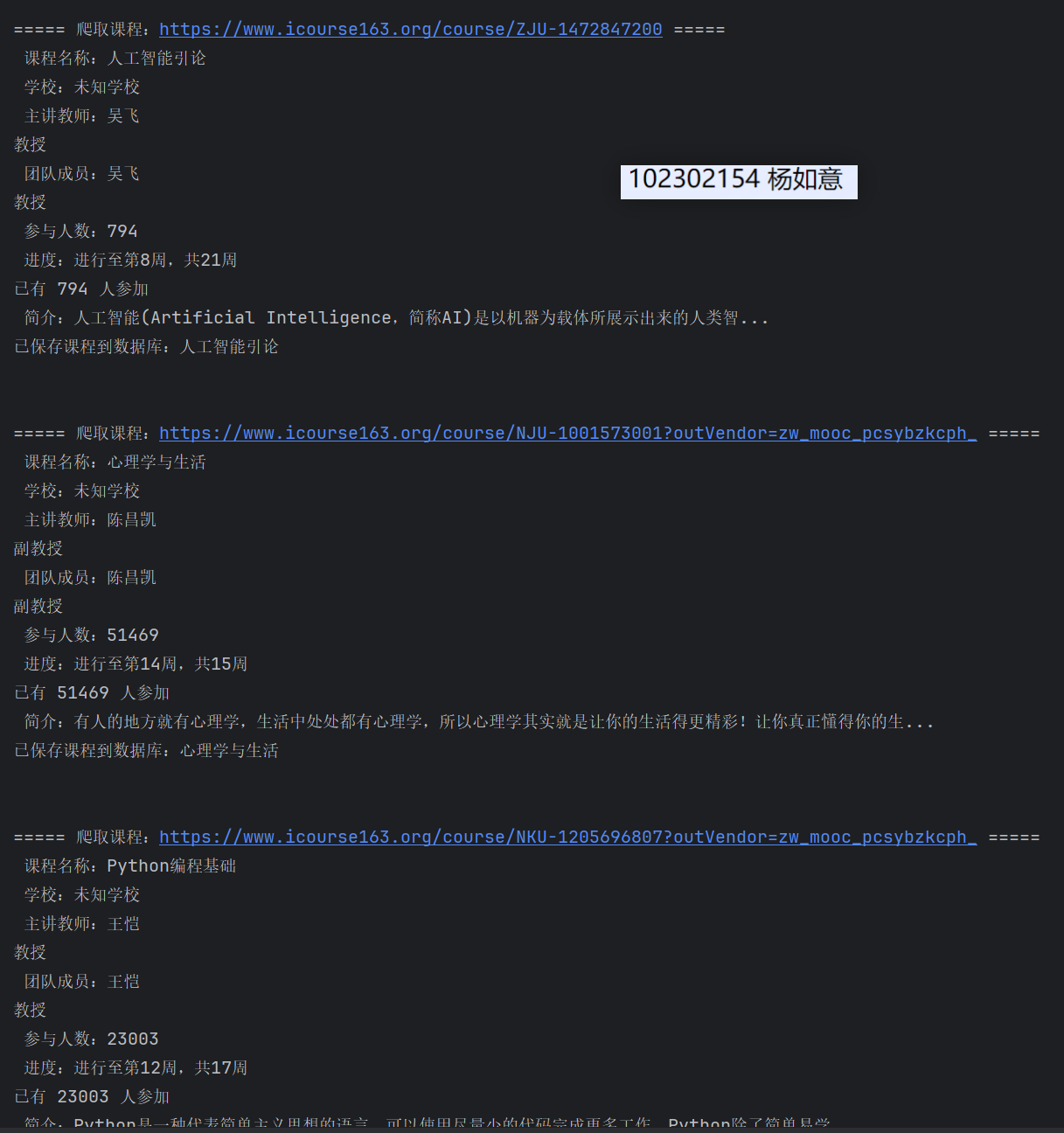
心得体会
一开始模拟登录就卡了壳,登录按钮藏在 iframe 里,直接定位根本找不到,后来学会切换 iframe,还用上显式等待,总算顺利完成登录。
作业③:
要求:
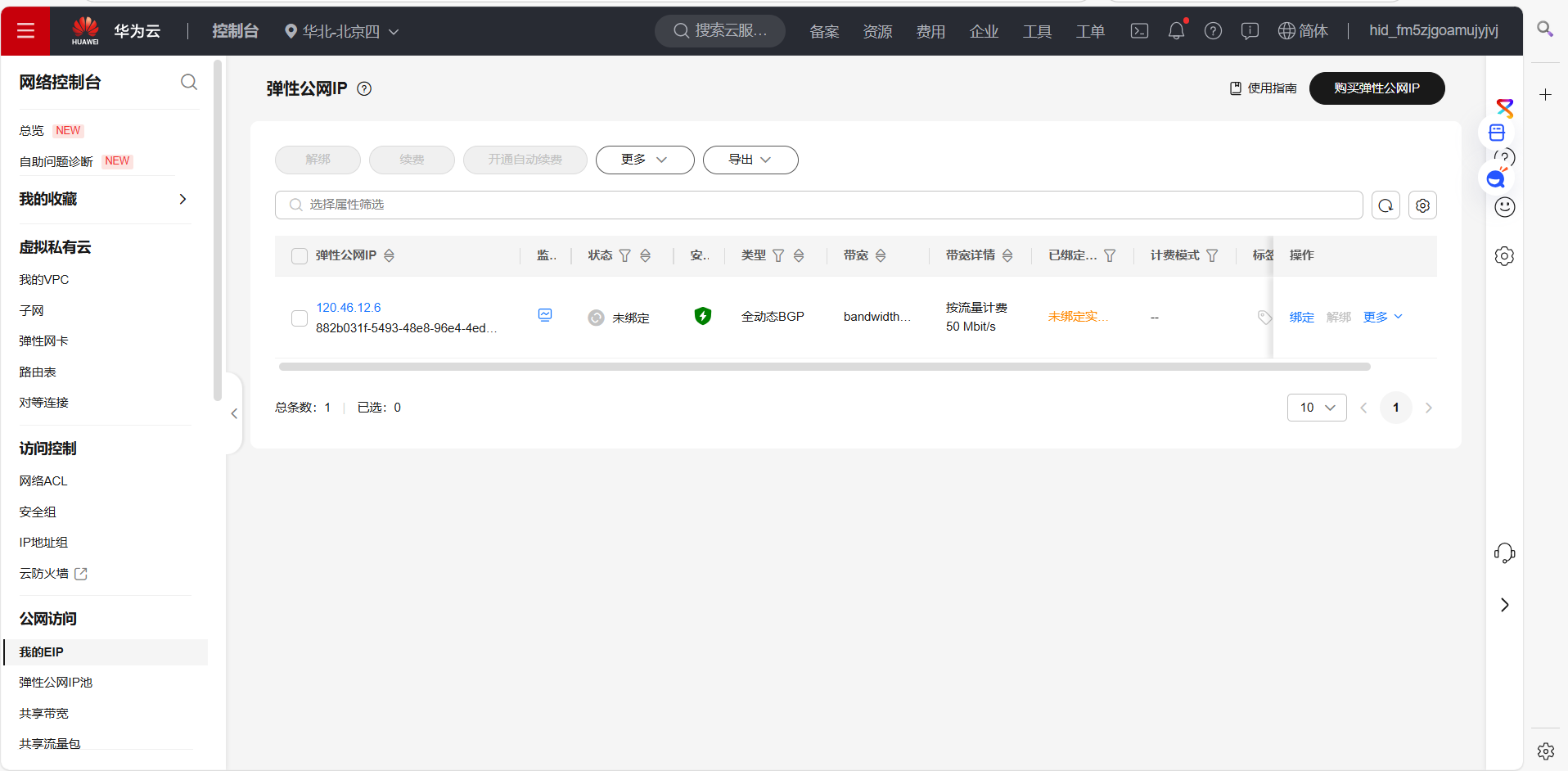
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
1.申请弹性公网IP
2.开通MapReduce服务
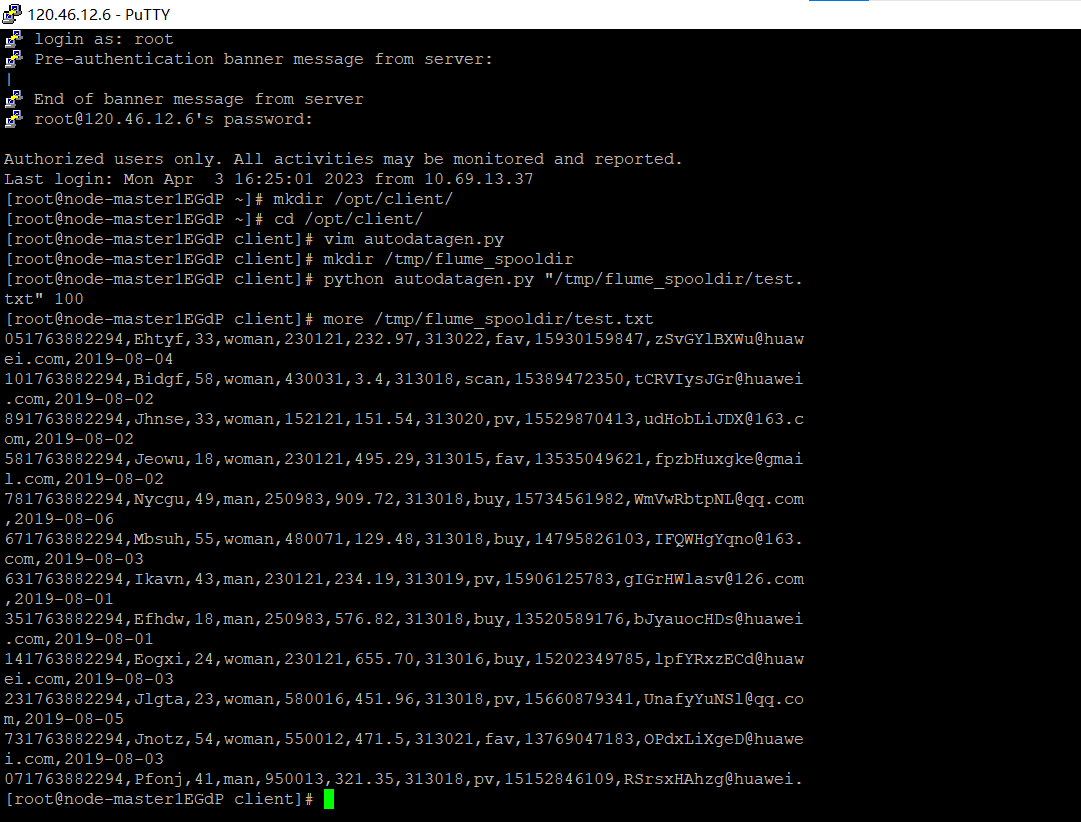
3.Python脚本生成测试数据
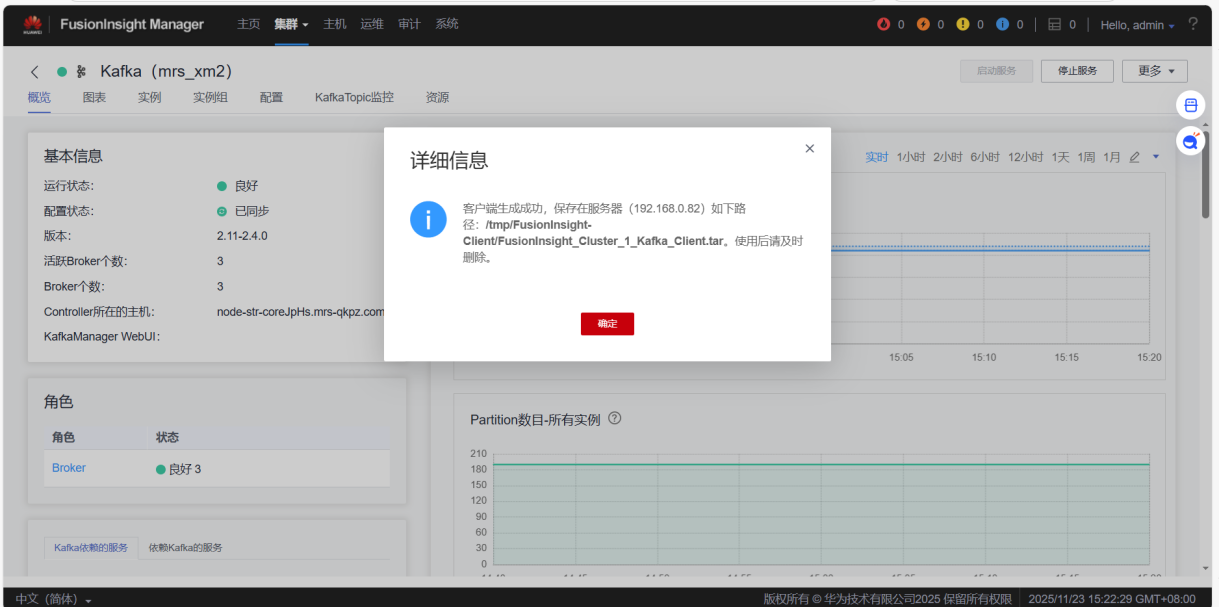
4.配置Kafka
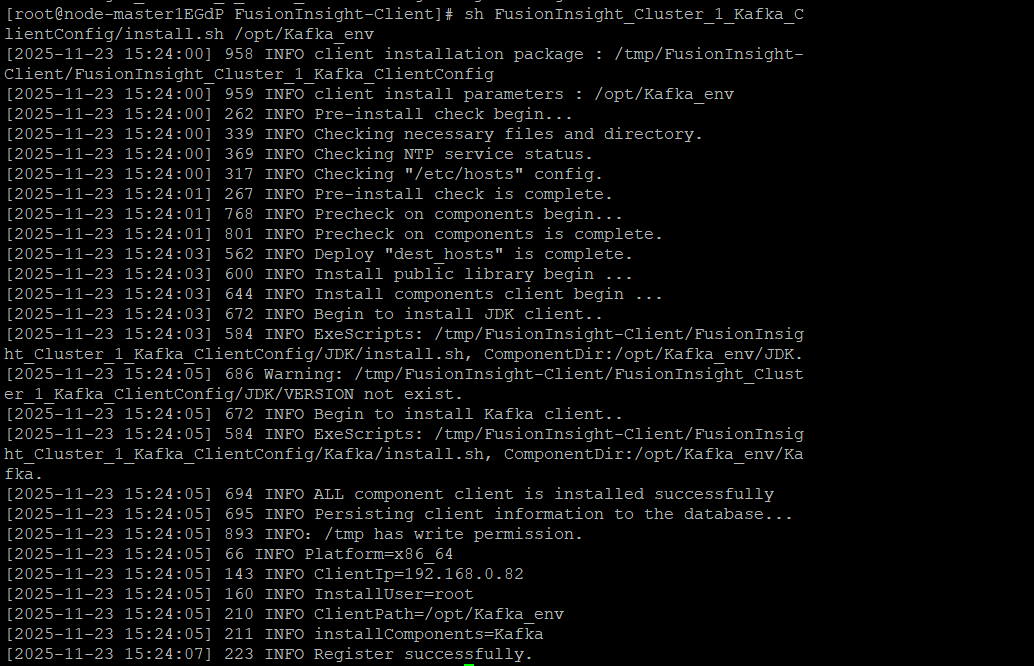
5.安装Kafka客户端
6.安装Flume客户端
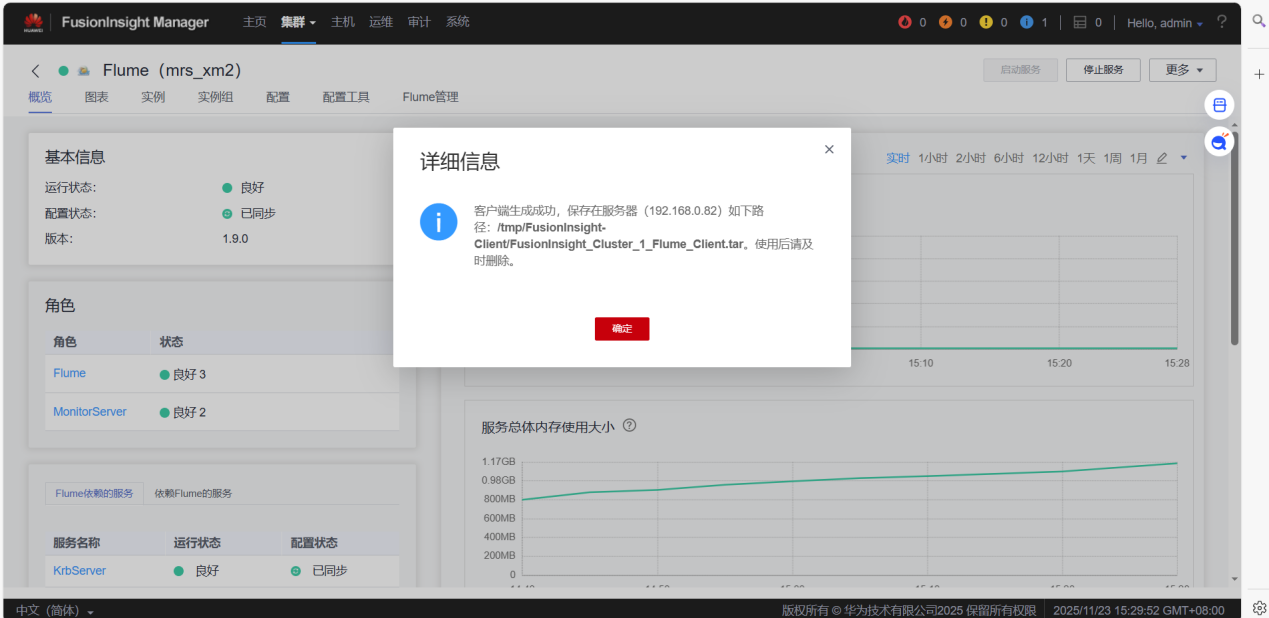
7.安装Flume运行环境
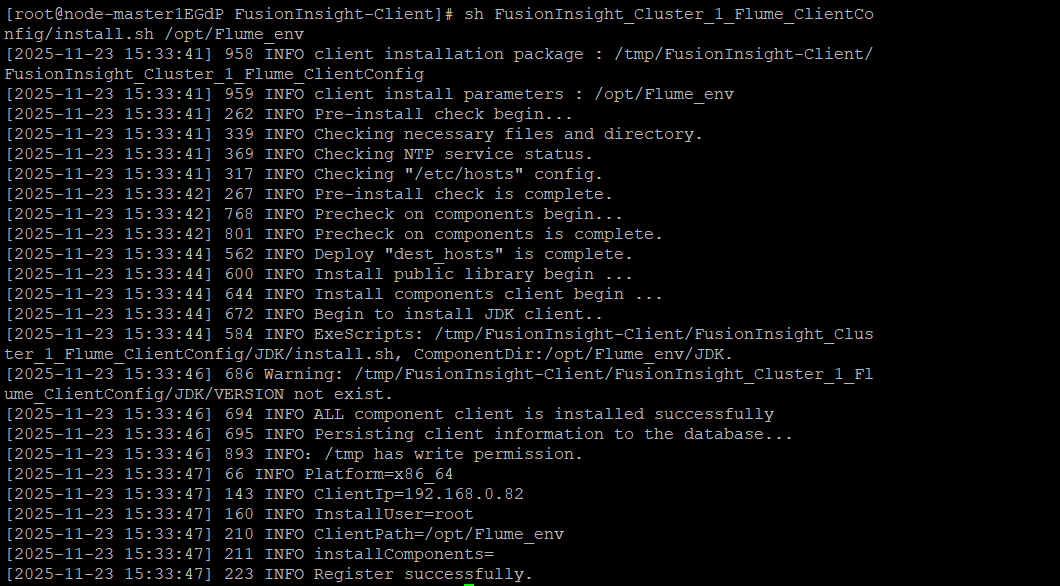
8.安装Flume客户端
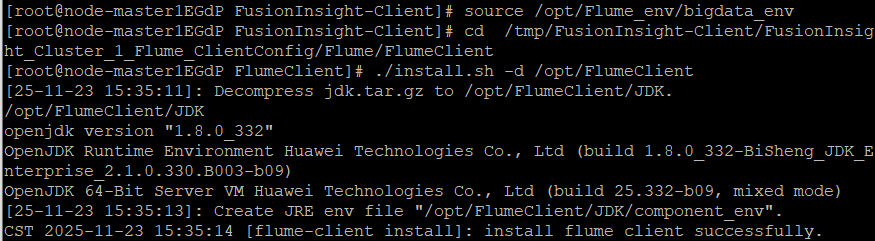
9.配置Flume采集数据
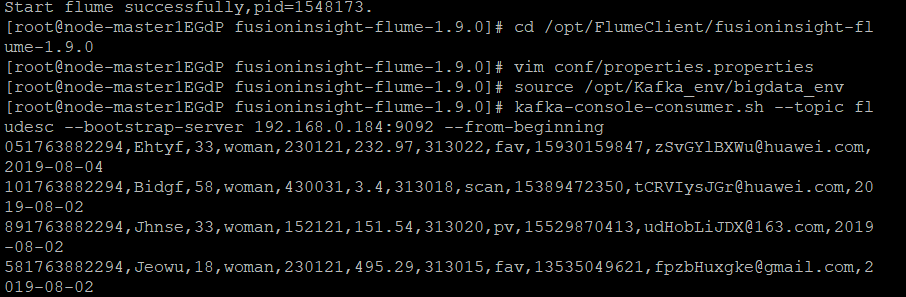
10.创建消费者消费kafka中的数据
心得体会:
实时分析开发实战环节,Python 脚本生成测试数据还算顺利,可配置 Kafka 时就卡了壳,topic 创建和参数调试反复出错,排查半天才发现是端口权限没开放。安装 Flume 客户端时,依赖包的版本兼容问题又让我折腾了好久,整个实验下来,我不仅掌握了 MapReduce、Kafka、Flume 的核心用法,还熟练了 Xshell 远程操作技能,更明白了大数据服务协同工作的逻辑。
代码地址
https://gitee.com/yang-ruyi777/2025_crawl_project/tree/homework4/作业4