别再只懂二分类!逻辑回归+Softmax多分类实战,保姆级教程奉上 - 详解
目录
一、引言
二、核心原理
01、Softmax函数
02、Softmax回归
三、代码实战
四、可视化图表
01、特征重要性对比
02、预测概率分布
03、分类边界对比
一、引言
提到逻辑回归,多数人第一反应是,哦,那个做二分类的算法。比如判断邮件是否为垃圾邮件、用户是否会点击广告。但实际业务中,我们常常遇到更复杂的分类需求,比如根据用户行为预测其属于高价值客户,潜力客户还是流失风险客户。逻辑回归![]() https://mp.weixin.qq.com/s?__biz=MzE5MTcyOTQwMw==&mid=2247484873&idx=1&sn=db0f89834606b6e0fd07082bb5649107&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzE5MTcyOTQwMw==&mid=2247484873&idx=1&sn=db0f89834606b6e0fd07082bb5649107&scene=21#wechat_redirect
今天就带大家突破逻辑回归的二分类局限,重点分享如何用Softmax回归实现多分类任务。
二、核心原理
01、Softmax函数
Softmax函数的作用,就是把这些得分转化为0-1之间的概率值,且所有类别概率之和为1。

02、Softmax回归
Softmax 回归的流程主要分为以下3步。
1.线性预测得分:先通过线性模型计算每个类别的原始得分。
2.Softmax概率转换:将所有类别的原始得分代入Softmax函数,得到每个类别的概率。
3.交叉熵损失:为了让模型预测的概率接近真实标签,我们使用交叉熵损失来衡量误差。
三、代码实战
接下来我们用鸢尾花数据集做实战,该数据集包含3种鸢尾花(Setosa、Versicolor、Virginica),共150个样本,每个样本有4 个特征(花瓣长度、花瓣宽度、花萼长度、花萼宽度)。
我们会用Softmax回归和决策树分别训练模型,看看两种算法的分类效果差异。
在scikit-learn中,逻辑回归默认支持多分类,所以可以换成multinomial参数就是Softmax回归。
# 初始化Softmax回归模型(solver选'sag',适合多分类且数据量大的场景)
softmax_model = LogisticRegression(
multi_class='multinomial', # 启用Softmax回归
solver='sag', # 优化器
max_iter=1000, # 最大迭代次数
random_state=42
)
# 训练模型
softmax_model.fit(X_train_scaled, y_train)
# 在测试集上预测
y_pred_softmax = softmax_model.predict(X_test_scaled)
y_pred_prob_softmax = softmax_model.predict_proba(X_test_scaled) # 输出每个类别的概率
# 计算准确率
accuracy_softmax = accuracy_score(y_test, y_pred_softmax)
print("Softmax回归测试集准确率:", round(accuracy_softmax, 4))
# 输出分类报告(精确率、召回率、F1-score)
print("\nSoftmax回归分类报告:")
print(classification_report(y_test, y_pred_softmax, target_names=['类别0', '类别1', '类别2']))下面我们再训练一个决策树模型做对比。
# 初始化决策树模型
dt_model = DecisionTreeClassifier(
max_depth=3, # 限制树深度,避免过拟合
random_state=42
)
# 训练模型
dt_model.fit(X_train, y_train) # 决策树对特征尺度不敏感,无需标准化
# 在测试集上预测
y_pred_dt = dt_model.predict(X_test)
# 计算准确率
accuracy_dt = accuracy_score(y_test, y_pred_dt)
print("决策树测试集准确率:", round(accuracy_dt, 4))
# 输出分类报告
print("\n决策树分类报告:")
print(classification_report(y_test, y_pred_dt, target_names=['类别0', '类别1', '类别2']))四、可视化图表
先说结论,在本次三分类问题上,Softmax回归准确率为0.9333,决策树准确率为0.9667。虽然Softmax回归的准确率略逊一筹,但是Softmax模型简单、可解释性强,可以作为一个基准模型与其他模型进行对比。
01、特征重要性对比
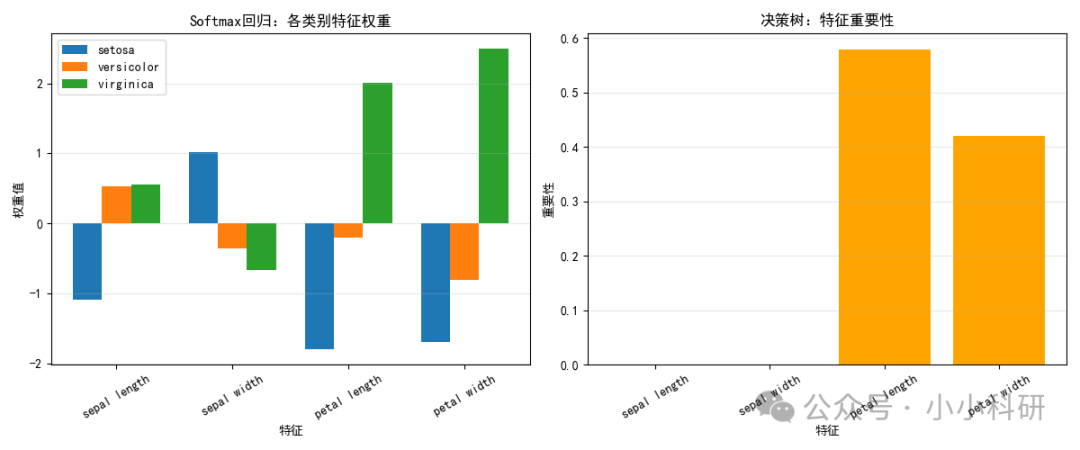
在Softmax回归中,每个类别的权重绝对值大小可以反映出特征对该类别的影响,决策树则直接输出特征重要性。
如下图,我们可以看出特征重要性,这里sepal是花萼,petal是花瓣。
1.花瓣特征(长度、宽度)是鸢尾花分类的核心依据:Softmax回归中virginica类的花瓣权重极大,决策树中花瓣特征重要性远高于花萼。
2.花萼特征的作用更偏向特定类别:Softmax中花萼对setosa类的区分有一定作用,但决策树中花萼整体区分能力弱。
3.versicolor类的特征区分性弱:Softmax中versicolor类的所有特征权重都接近0,说明它的特征很模糊,难通过单一特征与其他类别明确区分。
02、预测概率分布
如下图,大部分样本,模型对真实类别的预测概率很高,置信度强。少数样本对真实类别的预测概率相对低一些,置信度稍弱,但仍能正确分类。整体来看,Softmax 回归模型在前10个测试样本上表现出了较好的分类能力,大部分情况下能准确且高置信度地预测样本类别。

03、分类边界对比
如下图,Softmax回归的线性边界试图用直线将不同类别样本分开。决策树的阶梯状边界通过更灵活的分段划分。
相比之下,决策树的边界对当前样本分布的拟合更优。

代码获取:https://pan.quark.cn/s/063967171164?pwd=sr8A
提取码:sr8A
https://mp.weixin.qq.com/s/d3ZFeln4R8sPFVymG3wIZA![]() https://mp.weixin.qq.com/s/d3ZFeln4R8sPFVymG3wIZA
https://mp.weixin.qq.com/s/d3ZFeln4R8sPFVymG3wIZA
请点击上方链接,关注【小小科研】公众号,了解更多详细内容哦!
感谢支持!