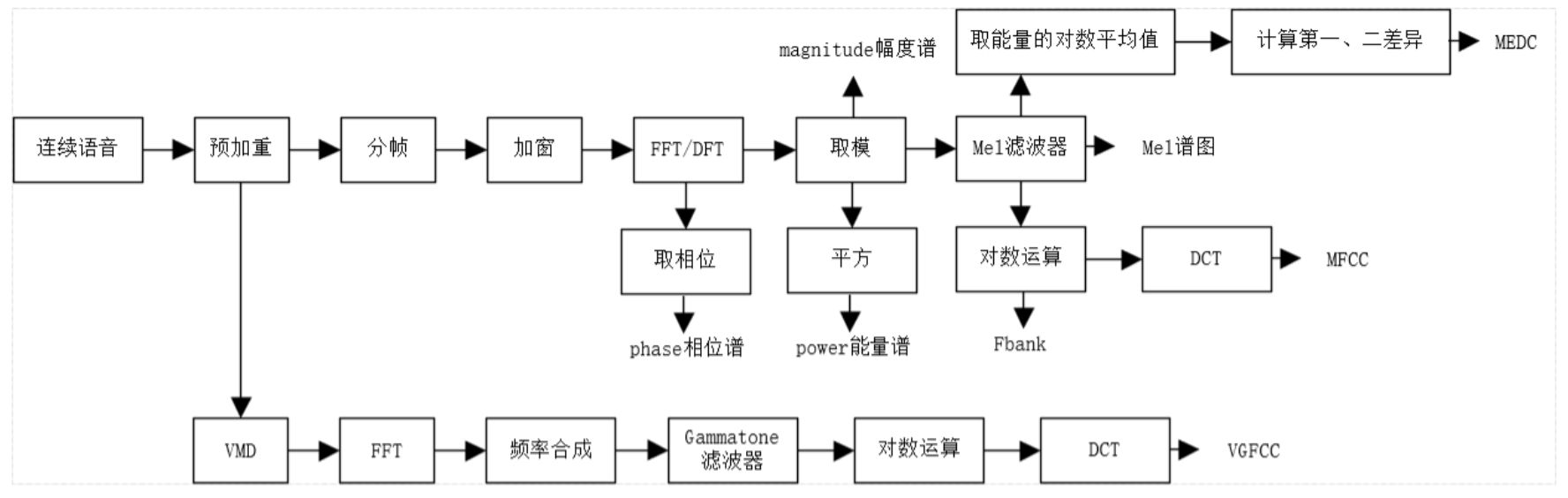
注:FFT(快速傅里叶变换);DFT(离散傅里叶变换);DCT(离散余弦变换);VMD(变分模态分解)
音频文件读取:
import torchaudio
def open_audio(audio_file): # Load an audio file.sig, sr = torchaudio.load(audio_file) # 加载音频文件return sig, sr # 音频时间序列, 音频采样率
通道数调整:
import torch
def re_channel(aud, new_channel): # 统一音频通道数sig, sr = aud # aud=(音频时间序列, 音频采样率)if sig.shape[0] == new_channel: # 保持通道数return aud # Nothing to doif new_channel == 1: # 转换成单通道resign = sig[:1, :] # Convert from stereo to mono by selecting only the first channelelse: # 转换成多通道resign = torch.cat([sig, sig]) # Convert from mono to stereo by duplicating the first channelreturn resign, sr
采样率调整:
import torch
import torchaudio
def resample(aud, new_sr): # 标准化采样率sig, sr = audif sr == new_sr: # 若采样率与初始相同,则不需重新采样return aud # Nothing to donum_channels = sig.shape[0] # 获取原通道个数resign = torchaudio.transforms.Resample(sr, new_sr)(sig[:1, :]) # Resample first channelif num_channels > 1:# Resample the second channel and merge both channelsre_two = torchaudio.transforms.Resample(sr, new_sr)(sig[1:, :])resign = torch.cat([resign, re_two])return resign, new_sr
音频长度调整:
import torchaudio
import random
def pad_trunc(aud, max_ms): # 调整为相同长度sig, sr = audnum_rows, sig_len = sig.shapemax_len = sr // 1000 * max_msif sig_len > max_len: # 裁剪多余部分sig = sig[:, :max_len] # Truncate the signal to the given lengthelif sig_len < max_len: # 全零补充# Length of padding to add at the beginning and end of the signalpad_begin_len = random.randint(0, max_len - sig_len)pad_end_len = max_len - sig_len - pad_begin_lenpad_begin = torch.zeros((num_rows, pad_begin_len)) # Pad with 0spad_end = torch.zeros((num_rows, pad_end_len))sig = torch.cat((pad_begin, sig, pad_end), 1) # inputs,dim=1return sig, sr
获取谱图特征:
from torchaudio import transforms
def spectro_gram(aud, feature, n_mel=64, n_fft=1024, hop_len=None): # 谱图sig, sr = audtop_db = 80feature_choice = feature # 谱图;Mel谱图;MFCC# spec has shape [channel, n_mel, time], where channel is mono, stereo etc# 音频信号的采样率,win_length窗口大小(默认:n_fft,FFT 的大小),STFT 窗口之间的跳跃长度(默认:win_length // 2),梅尔滤波器组的数量# MelSpectrogram返回了一个函数名,故后面加了函数需要输入的值if feature_choice == 'Spectrogram':spec = transforms.Spectrogram(n_fft=n_fft, hop_length=hop_len)(sig)# Convert to decibelsspec = transforms.AmplitudeToDB(top_db=top_db)(spec)elif feature_choice == 'MelSpectrogram':spec = transforms.MelSpectrogram(sr, n_fft=n_fft, hop_length=hop_len, n_mels=n_mel)(sig)# Convert to decibelsspec = transforms.AmplitudeToDB(top_db=top_db)(spec)else:spec = transforms.MFCC(sr, melkwargs={"n_fft": n_fft, "hop_length": hop_len, "n_mels": n_mel})(sig)return spec
获取3D谱图特征(谱图及其一阶差分和二阶差分):
import numpy as np
import torch
def delta_delta(spector, h):right = np.concatenate([spector[:, 0].reshape((h, -1)), spector], axis=1)[:, :-1]delta = (spector - right)[:, 1:]delta_pad = delta[:, 0].reshape((h, -1))delta = np.concatenate([delta_pad, delta], axis=1)return delta
def get_3d_spec(spector, moments=None): #spector:谱图if moments is not None:(base_mean, base_std, delta_mean, delta_std, delta2_mean, delta2_std) = momentselse:base_mean, delta_mean, delta2_mean = (0, 0, 0)base_std, delta_std, delta2_std = (1, 1, 1)h, w = spector.shapedelta = delta_delta(spector, h)delta2 = delta_delta(delta, h)base = (spector - base_mean) / base_stddelta = (delta - delta_mean) / delta_stddelta2 = (delta2 - delta2_mean) / delta2_stdstacked = [arr.reshape((h, w, 1)) for arr in (base, delta, delta2)]return torch.from_numpy(np.concatenate(stacked, axis=2))
注:一阶差分就是离散函数中连续相邻两项之差【定义X(k),则Y(k)=X(k+1)-X(k)就是此函数的一阶差分,即当前语音帧与前一帧之间的关系, 体现帧与帧(相邻两帧)之间的联系】
二阶差分表示的是一阶差分与一阶差分之间的关系【在一阶差分的基础上,Z(k)=Y(k+1)-Y(k)=X(k+2)-2*X(k+1)+X(k)为此函数的二阶差分,即前一阶差分与后一阶差分之间的关系,体现到帧上就是相邻三帧之间的动态关系】
绘制音频波形:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import numpy as np
# 显示语音时域波形
time = np.arange(0, len(dur_aud[0][0])) * (1.0 / dur_aud[1]) #dur_aud=(音频时间序列, 音频采样率)
plt.plot(time, dur_aud[0][0])
plt.title("语音信号时域波形", fontproperties='Microsoft YaHei')
plt.xlabel("时长(秒)", fontproperties='SimHei')
plt.ylabel("振幅", fontproperties='SimHei')
plt.savefig("./img_data/语音信号时域波形图", dpi=600)
plt.show()