from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge from sklearn.metrics import mean_squared_error from sklearn.externals import joblibdef linear1():"""正规方程的优化方法对波士顿房价进行预测:return:"""# 1)获取数据boston = load_boston()# 2)划分数据集x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)# 3)标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)预估器estimator = LinearRegression()estimator.fit(x_train, y_train)# 5)得出模型print("正规方程-权重系数为:\n", estimator.coef_)print("正规方程-偏置为:\n", estimator.intercept_)# 6)模型评估y_predict = estimator.predict(x_test)print("预测房价:\n", y_predict)error = mean_squared_error(y_test, y_predict)print("正规方程-均方误差为:\n", error)return Nonedef linear2():"""梯度下降的优化方法对波士顿房价进行预测:return:"""# 1)获取数据boston = load_boston()print("特征数量:\n", boston.data.shape)# 2)划分数据集x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)# 3)标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)预估器estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000, penalty="l1")estimator.fit(x_train, y_train)# 5)得出模型print("梯度下降-权重系数为:\n", estimator.coef_)print("梯度下降-偏置为:\n", estimator.intercept_)# 6)模型评估y_predict = estimator.predict(x_test)print("预测房价:\n", y_predict)error = mean_squared_error(y_test, y_predict)print("梯度下降-均方误差为:\n", error)return Nonedef linear3():"""岭回归对波士顿房价进行预测:return:"""# 1)获取数据boston = load_boston()print("特征数量:\n", boston.data.shape)# 2)划分数据集x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)# 3)标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)预估器# estimator = Ridge(alpha=0.5, max_iter=10000)# estimator.fit(x_train, y_train)# 保存模型# joblib.dump(estimator, "my_ridge.pkl")# 加载模型estimator = joblib.load("my_ridge.pkl")# 5)得出模型print("岭回归-权重系数为:\n", estimator.coef_)print("岭回归-偏置为:\n", estimator.intercept_)# 6)模型评估y_predict = estimator.predict(x_test)print("预测房价:\n", y_predict)error = mean_squared_error(y_test, y_predict)print("岭回归-均方误差为:\n", error)return Noneif __name__ == "__main__":# 代码1:正规方程的优化方法对波士顿房价进行预测 linear1()# 代码2:梯度下降的优化方法对波士顿房价进行预测 linear2()# 代码3:岭回归对波士顿房价进行预测linear3()
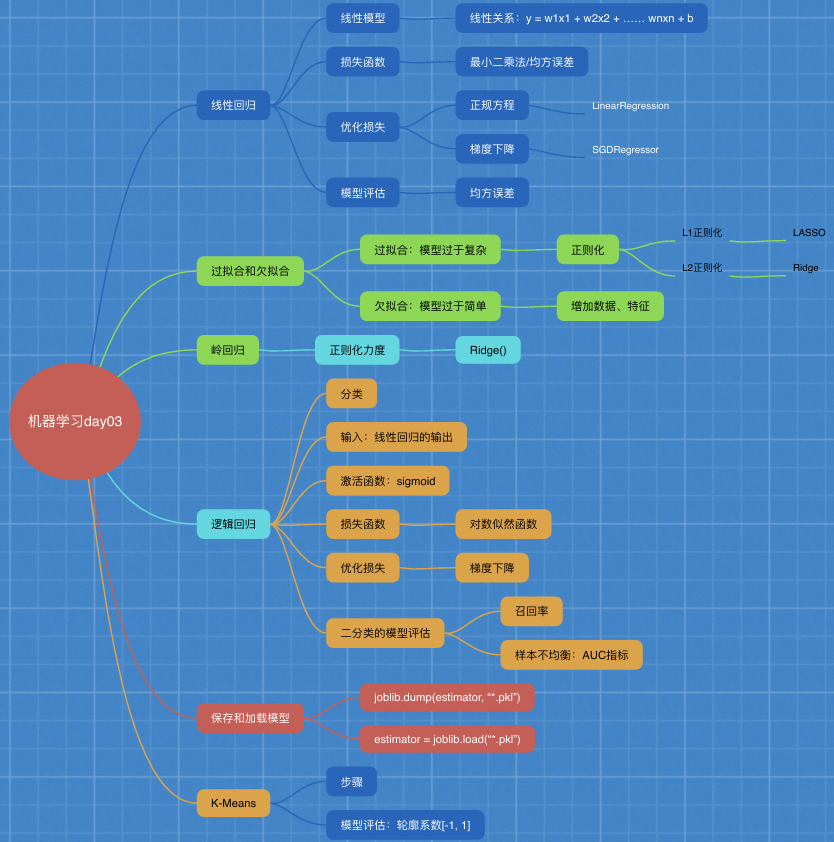
4.1 线性回归回归问题:目标值 - 连续型的数据4.1.1 线性回归的原理2 什么是线性回归函数关系 特征值和目标值线型模型线性关系y = w1x1 + w2x2 + w3x3 + …… + wnxn + b= wTx + b数据挖掘基础y = kx + by = w1x1 + w2x2 + by = 0.7x1 + 0.3x2期末成绩:0.7×考试成绩+0.3×平时成绩[[90, 85],[]][[0.3],[0.7]][8, 2] * [2, 1] = [8, 1]广义线性模型非线性关系?线性模型自变量一次y = w1x1 + w2x2 + w3x3 + …… + wnxn + b参数一次y = w1x1 + w2x1^2 + w3x1^3 + w4x2^3 + …… + b线性关系&线性模型线性关系一定是线性模型线性模型不一定是线性关系4.1.2 线性回归的损失和优化原理(理解记忆)目标:求模型参数模型参数能够使得预测准确真实关系:真实房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率随意假定:预测房子价格 = 0.25×中心区域的距离 + 0.14×城市一氧化氮浓度 + 0.42×自住房平均房价 + 0.34×城镇犯罪率损失函数/cost/成本函数/目标函数:最小二乘法优化损失优化方法?正规方程天才 - 直接求解W拓展:1)y = ax^2 + bx + cy' = 2ax + b = 0x = - b / 2a2)a * b = 1b = 1 / a = a ^ -1A * B = E[[1, 0, 0],[0, 1, 0],[0, 0, 1]]B = A ^ -1梯度下降勤奋努力的普通人试错、改进4.1.4 波士顿房价预测流程:1)获取数据集2)划分数据集3)特征工程:无量纲化 - 标准化4)预估器流程fit() --> 模型coef_ intercept_5)模型评估回归的性能评估:均方误差4 正规方程和梯度下降对比 4.2 欠拟合与过拟合训练集上表现得好,测试集上不好 - 过拟合4.2.1 什么是过拟合与欠拟合欠拟合学习到数据的特征过少解决:增加数据的特征数量过拟合原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点解决:正则化L1损失函数 + λ惩罚项LASSOL2 更常用损失函数 + λ惩罚项Ridge - 岭回归 4.3 线性回归的改进-岭回归4.3.1 带有L2正则化的线性回归-岭回归alpha 正则化力度=惩罚项系数 4.4 分类算法-逻辑回归与二分类4.4.1 逻辑回归的应用场景广告点击率 是否会被点击是否为垃圾邮件是否患病是否为金融诈骗是否为虚假账号正例 / 反例4.4.2 逻辑回归的原理线型回归的输出 就是 逻辑回归 的 输入激活函数sigmoid函数 [0, 1]1/(1 + e^(-x))假设函数/线性模型1/(1 + e^(-(w1x1 + w2x2 + w3x3 + …… + wnxn + b)))损失函数(y_predict - y_true)平方和/总数逻辑回归的真实值/预测值 是否属于某个类别对数似然损失log 2 x优化损失梯度下降4.4.4 案例:癌症分类预测-良/恶性乳腺癌肿瘤预测恶性 - 正例流程分析:1)获取数据读取的时候加上names2)数据处理处理缺失值3)数据集划分4)特征工程:无量纲化处理-标准化5)逻辑回归预估器6)模型评估真的患癌症的,能够被检查出来的概率 - 召回率4.4.5 分类的评估方法1 精确率与召回率1 混淆矩阵TP = True PossitiveFN = False Negative2 精确率(Precision)与召回率(Recall)精确率召回率 查得全不全工厂 质量检测 次品 召回率3 F1-score 模型的稳健型总共有100个人,如果99个样本癌症,1个样本非癌症 - 样本不均衡不管怎样我全都预测正例(默认癌症为正例) - 不负责任的模型准确率:99%召回率:99/99 = 100%精确率:99%F1-score: 2*99%/ 199% = 99.497%AUC:0.5TPR = 100%FPR = 1 / 1 = 100%2 ROC曲线与AUC指标1 知道TPR与FPRTPR = TP / (TP + FN) - 召回率所有真实类别为1的样本中,预测类别为1的比例FPR = FP / (FP + TN)所有真实类别为0的样本中,预测类别为1的比例 4.5 模型保存和加载 4.6 无监督学习-K-means算法4.6.1 什么是无监督学习没有目标值 - 无监督学习4.6.2 无监督学习包含算法聚类K-means(K均值聚类)降维PCA4.6.3 K-means原理4.6.5 案例:k-means对Instacart Market用户聚类k = 3流程分析:降维之后的数据1)预估器流程2)看结果3)模型评估4.6.6 Kmeans性能评估指标轮廓系数如果b_i>>a_i:趋近于1效果越好,b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。4.6.7 K-means总结应用场景:没有目标值分类