LLaMA-Factory
 Warp, the agentic terminal for developers Available for MacOS, Linux, & Windows |  |
|---|
Easily fine-tune 100+ large language models with zero-code CLI and Web UI
- Various models: LLaMA, LLaVA, Mistral, Mixtral-MoE, Qwen, Qwen2-VL, DeepSeek, Yi, Gemma, ChatGLM, Phi, etc.
- Integrated methods: (Continuous) pre-training, (multimodal) supervised fine-tuning, reward modeling, PPO, DPO, KTO, ORPO, etc.
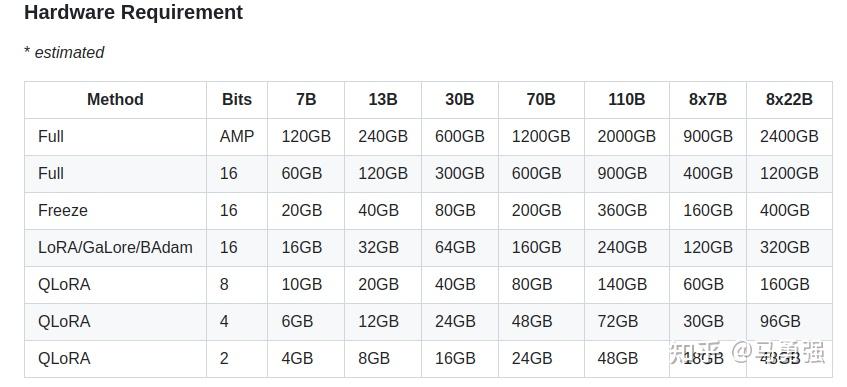
- Scalable resources: 16-bit full-tuning, freeze-tuning, LoRA and 2/3/4/5/6/8-bit QLoRA via AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ.
- Advanced algorithms: GaLore, BAdam, APOLLO, Adam-mini, Muon, OFT, DoRA, LongLoRA, LLaMA Pro, Mixture-of-Depths, LoRA+, LoftQ and PiSSA.
- Practical tricks: FlashAttention-2, Unsloth, Liger Kernel, RoPE scaling, NEFTune and rsLoRA.
- Wide tasks: Multi-turn dialogue, tool using, image understanding, visual grounding, video recognition, audio understanding, etc.
- Experiment monitors: LlamaBoard, TensorBoard, Wandb, MLflow, SwanLab, etc.
- Faster inference: OpenAI-style API, Gradio UI and CLI with vLLM worker or SGLang worker.
| Support Date | Model Name |
|---|---|
| Day 0 | Qwen3 / Qwen2.5-VL / Gemma 3 / GLM-4.1V / InternLM 3 / MiniCPM-o-2.6 |
| Day 1 | Llama 3 / GLM-4 / Mistral Small / PaliGemma2 / Llama 4 |
https://zhuanlan.zhihu.com/p/695287607
开源大模型如LLaMA,Qwen,Baichuan等主要都是使用通用数据进行训练而来,其对于不同下游的使用场景和垂直领域的效果有待进一步提升,衍生出了微调训练相关的需求,包含预训练(pt),指令微调(sft),基于人工反馈的对齐(rlhf
)等全链路。但大模型训练对于显存和算力的要求较高,同时也需要下游开发者对大模型本身的技术有一定了解,具有一定的门槛。
LLaMA-Factory项目的目标是整合主流的各种高效训练微调技术,适配市场主流开源模型,形成一个功能丰富,适配性好的训练框架。项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用。同时借鉴 Stable Diffsion WebUI相关,本项目提供了基于gradio
的网页版工作台,方便初学者可以迅速上手操作,开发出自己的第一个模型。
https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README.md
Alpaca Format
- Example dataset
In supervised fine-tuning, the instruction column will be concatenated with the input column and used as the user prompt, then the user prompt would be instruction\ninput. The output column represents the model response.
For reasoning models, if the dataset contains chain-of-thought (CoT), the CoT needs to be placed in the model responses, such as <think>cot</think>output.
The system column will be used as the system prompt if specified.
The history column is a list consisting of string tuples representing prompt-response pairs in the history messages. Note that the responses in the history will also be learned by the model in supervised fine-tuning.
[{"instruction": "user instruction (required)","input": "user input (optional)","output": "model response (required)","system": "system prompt (optional)","history": [["user instruction in the first round (optional)", "model response in the first round (optional)"],["user instruction in the second round (optional)", "model response in the second round (optional)"]]}
]
Regarding the above dataset, the dataset description in dataset_info.json should be:
"dataset_name": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
Tip
If the model has reasoning capabilities (e.g. Qwen3) but the dataset does not contain chain-of-thought (CoT), LLaMA-Factory will automatically add empty CoT to the data. When enable_thinking is True (slow thinking, by default), the empty CoT will be added to the model responses and loss computation will be considered; otherwise (fast thinking), it will be added to the user prompts and loss computation will be ignored. Please keep the enable_thinking parameter consistent during training and inference.
If you want to train data containing CoT with slow thinking and data without CoT with fast thinking, you can set enable_thinking to None. However, this feature is relatively complicated and should be used with caution.
- Example dataset
In pre-training, only the text column will be used for model learning.
[{"text": "document"},{"text": "document"}
]
Regarding the above dataset, the dataset description in dataset_info.json should be:
"dataset_name": {"file_name": "data.json","columns": {"prompt": "text"}
}
Preference datasets are used for reward modeling, DPO training, ORPO and SimPO training.
It requires a better response in chosen column and a worse response in rejected column.
[{"instruction": "user instruction (required)","input": "user input (optional)","chosen": "chosen answer (required)","rejected": "rejected answer (required)"}
]
Regarding the above dataset, the dataset description in dataset_info.json should be:
"dataset_name": {"file_name": "data.json","ranking": true,"columns": {"prompt": "instruction","query": "input","chosen": "chosen","rejected": "rejected"}
}