本文分享自天翼云开发者社区《警惕大数据处理中的“检查者悖论》.作者:王****淋
什么是检查者悖论:
观察的角度不同,得出的统计结论也不同。有时又称为"候车悖论", "等待时间悖论"
为了形象说明,我们设计了一种模拟场景: 班级人数统计,来用实例说明这个问题
模拟场景: 班级人数统计
小明与小华要完成一个任务:统计学校中的 平均班级人数。但二人的实施方案不同:
1)小明找到了教务处老师,拿到了一份每班级人数统计名单。 于是他计算到了班级平均人数
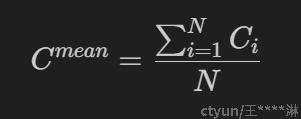
, 其中N为班级数量。
2)小华则不同, 他选择去街头询问。小华在校园中随机询问了M人, 得到了M个数字, 每个数字即为该被询问的同学所在的班级人数。于是他计算到了班级平均人数
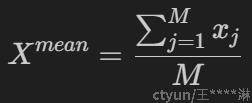
显然,二者的答案是不同的:
假设此学校一共2个班级: 一个90人,另一个10人。则小明计算结果: C^{mean} = (10 + 90) / 2 = 50人。
假设小华抽了10人,在随机抽样的情况下,大约9人属于班级1,1人属于班级2,小华计算结果 X^{mean} = (10*1 + 90*9) / 10 = 82人
原因初探
很明显, 结果出现了偏差。是什么导致了这种情况?其实,这就是"检查悖论"
每个班级人数不均衡情况下:

新问题提出 ================
这时,自然的,我们提出一个问题:如果只有小华的数据,如何得到真实的统计结果,即班级平均人数 ?
EM算法可以胜任这一问题:EM是一类算法, 在包含隐变量的情况下,可以估算模型参数。
下面以班级平均人数统计问题为例:

其中,Si是已知量,ki为参数,sigma为隐变量,ni是观测变量。
上代码:
import randomdef print_dict(d:dict, title=""):k = [ki for ki in d.keys()]k.sort()s = []for ki in k:s.append(str(ki) + ": " + str(d[ki]))print(title, "{", "; ".join(s), "}")### 1. 数据集生成:通过随机数================================================ # 1.1. 首先生成每班人数 classes = 20 classes = classes // 2 * 2 class_members = [random.randint(40, 50) for i in range(classes//2)] + \[random.randint(100, 150) for i in range(classes//2)] \ class_dict = {} # 统计量: 人数为Ni的班级>共有多少个 for ci in class_members:if ci in class_dict.keys(): class_dict[ci] += 1else:class_dict[ci] = 1# 1.2. 在街上抽学生(依据每班人数) cy = random.choices(population=class_members,weights=[ci/sum(class_members) for ci in class_members], # 依概率抽样k = 400 # 街头抽样人数:应尽可能保证所有班级都有抽到 )asked_class_dict = {} # 统计量: 班级人数为Xi的人>共抽到了几个人 for cyi in cy: if cyi in asked_class_dict.keys(): asked_class_dict[cyi] += 1else:asked_class_dict[cyi] = 1### 2. EM ===================================================================== # EM \theta _0 init theta = {k: 1 for k in asked_class_dict.keys()}# run iter: ------------------ run_i = 20 while run_i > 0:run_i -= 1# 1. E-step: 依照{\theta}^t, 求P( Z | X, {\theta}^t )sigma = 0for k, v in theta.items():sigma += k * vsigma = len(cy) / sigma# 2. M-step: theta=argmax()for k, v in theta.items():theta[k] = round(asked_class_dict[k] / (k * v * sigma) * theta[k]) if theta[k] < 1: theta[k] = 1### 3. result showing ============================================================== print_dict(theta, "预测:{班级人数Ni: <人数为Ni的班级>共有多少个} \n\t") print_dict(class_dict, "真实:{班级人数Ni: <人数为Ni的班级>共有多少个} \n\t")N_class = 0 N_students = 0 for k, v in theta.items():N_students += k * vN_class += vprint("预测平均 = ", N_students / N_class) print("真实平均 = ", sum(class_members)/classes ) print("街头抽样平均 = ", sum(cy)/len(cy))