项目实战:中风数据分析
中风体检数据分析
1.数据导入
首先将所需要的包进行引用
importpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltimportseabornassns#设置中文显示plt.rcParams['font.sans-serif']=['SimHei']#设置负号显示plt.rcParams['axes.unicode_minus']=False然后导入数据
age_abs=pd.read_excel('healthcare-dataset-age_abs.xlsx')print(age_abs.head())stroke=pd.read_excel('healthcare-dataset-stroke.xlsx')print(stroke.head())编号 年龄 平均血糖 0 9046 67.0 228.69 1 51676 61.0 202.21 2 31112 80.0 105.92 3 60182 49.0 171.23 4 1665 79.0 174.12 编号 性别 高血压 是否结婚 工作类型 居住类型 体重指数 吸烟史 中风 0 9046 男 否 是 私人 城市 36.6 以前吸烟 是 1 51676 女 否 是 私营企业 农村 NaN 从不吸烟 是 2 31112 男 否 是 私人 农村 32.5 从不吸烟 是 3 60182 女 否 是 私人 城市 34.4 抽烟 是 4 1665 女 是 是 私营企业 农村 24.0 从不吸烟 是healthcare-dataset-age_abs.xlsx表格为患者的年龄和血糖信息,表格healthcare-dataset-stroke.xlsx为患者的基本信息(性别、年龄、体重、身高、血压、心率、是否患有中风等)。
2.查看数据信息(分布)
age_abs[['年龄','平均血糖']].describe().T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| 年龄 | 1767.0 | 45.858766 | 22.785222 | 0.08 | 28.000 | 49.00 | 64.000 | 82.00 |
| 平均血糖 | 1767.0 | 109.355444 | 47.983848 | 55.22 | 77.925 | 93.55 | 118.565 | 271.74 |
可见年龄的分布范围为[082],年龄分布较为平均,平均年龄为42岁,标准差为12岁。\ 平均血糖的分布范围为[55.22271.74],平均血糖为109.35544
age_abs.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 1767 entries, 0 to 1766 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 编号 1767 non-null int64 1 年龄 1767 non-null float64 2 平均血糖 1767 non-null float64 dtypes: float64(2), int64(1) memory usage: 41.5 KB可见age_abs表格中没有缺失值,所有数据均为数值型数据。
#查看中风数据的空缺情况stroke.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 1767 entries, 0 to 1766 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 编号 1767 non-null int64 1 性别 1767 non-null object 2 高血压 1767 non-null object 3 是否结婚 1767 non-null object 4 工作类型 1767 non-null object 5 居住类型 1767 non-null object 6 体重指数 1672 non-null float64 7 吸烟史 1767 non-null object 8 中风 1767 non-null object dtypes: float64(1), int64(1), object(7) memory usage: 124.4+ KB3.数据预处理
# 处理空缺值stroke=stroke.dropna()#合并表格data=pd.merge(age_abs,stroke,on='编号',how='inner')data.head()| 编号 | 年龄 | 平均血糖 | 性别 | 高血压 | 是否结婚 | 工作类型 | 居住类型 | 体重指数 | 吸烟史 | 中风 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9046 | 67.0 | 228.69 | 男 | 否 | 是 | 私人 | 城市 | 36.6 | 以前吸烟 | 是 |
| 1 | 31112 | 80.0 | 105.92 | 男 | 否 | 是 | 私人 | 农村 | 32.5 | 从不吸烟 | 是 |
| 2 | 60182 | 49.0 | 171.23 | 女 | 否 | 是 | 私人 | 城市 | 34.4 | 抽烟 | 是 |
| 3 | 1665 | 79.0 | 174.12 | 女 | 是 | 是 | 私营企业 | 农村 | 24.0 | 从不吸烟 | 是 |
| 4 | 56669 | 81.0 | 186.21 | 男 | 否 | 是 | 私人 | 城市 | 29.0 | 以前吸烟 | 是 |
data['中风'].value_counts()否 1463 是 209 Name: 中风, dtype: int64data=data.loc[data['中风']=='是'].reset_index(drop=True)#只需要中风数据data表格将进行后续的分析,分析出因素和中风的相关性。
4.数据分析与可视化
4.1 查看年龄和中风的相关性
#首先将连续年龄离散化labels=['青少年','青年','中年','壮年','老年']data['年龄级别']=pd.cut(data['年龄'],bins=[0,20,40,60,80,100],labels=labels)#按照年龄级别进行分组,统计每个组别的中风数量df_age=data.groupby('年龄级别')['中风'].count()#df_age#可视化df_age.plot.pie(autopct='%1.1f%%',labels=labels,startangle=90)plt.title("不同年龄级别中中风数量占比")plt.show()可见年龄为壮年的中风人数最多,其次是中年和老年,最后是青少年和青年。
4.2 查看其他类别数据和中风的相关性
#按照类别进行分组,统计每个组别的中风数量df_sex=data.groupby('性别').size()df_HBP=data.groupby('高血压').size()df_smoke=data.groupby('吸烟史').size()df_marrige=data.groupby('是否结婚').size()df_livetype=data.groupby('居住类型').size()df_worketype=data.groupby('工作类型').size()#可视化fig=plt.figure(figsize=(12,12),dpi=200)#创建画布,设置大小和分辨率plt.subplot(321)#创建子图,3行2列,第1个子图df_sex.plot.pie(autopct='%1.1f%%',startangle=90)plt.title("不同性别中中风数量占比")plt.subplot(322)df_HBP.plot.pie(autopct='%1.1f%%',startangle=90)plt.title("高血压中风数量占比")plt.subplot(323)df_smoke.plot.pie(autopct='%1.1f%%',startangle=90)plt.title("是否吸烟中风数量占比")plt.subplot(324)df_marrige.plot.pie(autopct='%1.1f%%',startangle=90)plt.title("是否结婚中风数量占比")plt.subplot(325)df_livetype.plot.pie(autopct='%1.1f%%',startangle=90)plt.title("居住类型中风数量占比")plt.subplot(326)df_worketype.plot.pie(autopct='%1.1f%%',startangle=90)plt.title("工作类型中风数量占比")plt.tight_layout()#调整子图间距plt.show()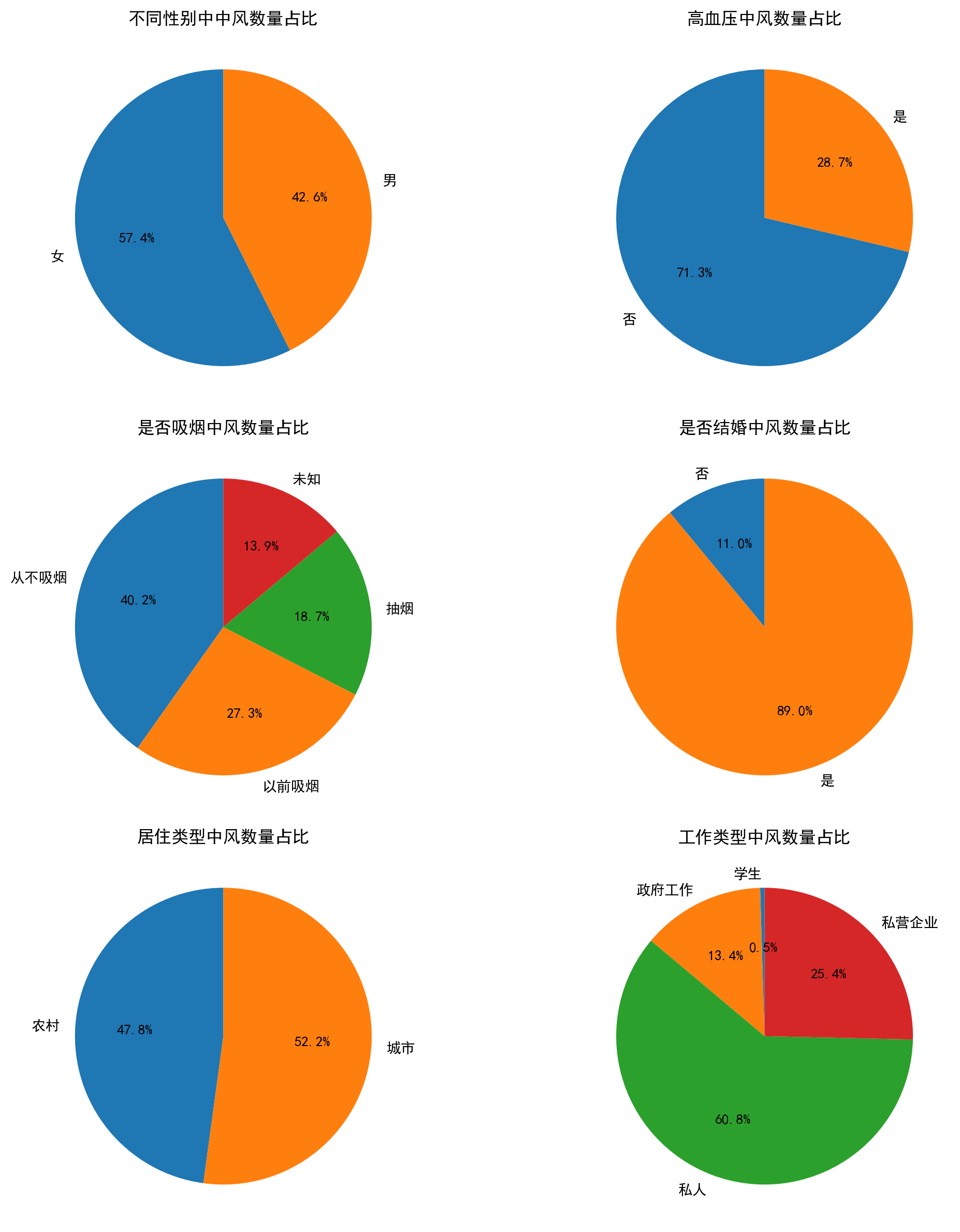结论分析:?
4.3 分析血糖和体重指数
plt.scatter(data['平均血糖'],data['体重指数'],s=0.8)plt.xlabel("平均血糖")plt.ylabel("体重指数")plt.title("平均血糖与体重指数关系")plt.show()结论?
# 1. 计算年龄、平均血糖、体重指数与中风的相关系数# 先将"中风"转为数值型data['中风_数值']=data['中风'].map({'是':1,'否':0})corr_age=data['年龄'].corr(data['中风_数值'])corr_glucose=data['平均血糖'].corr(data['中风_数值'])corr_bmi=data['体重指数'].corr(data['中风_数值'])print(f"年龄与中风的相关系数:{corr_age:.2f}")print(f"平均血糖与中风的相关系数:{corr_glucose:.2f}")print(f"体重指数与中风的相关系数:{corr_bmi:.2f}")年龄与中风的相关系数:nan 平均血糖与中风的相关系数:nan 体重指数与中风的相关系数:nan# 2. 对比中风与非中风人群的平均血糖、BMIstroke_compare=pd.DataFrame({'中风':['是','否'],'平均年龄':[data[data['中风']=='是']['年龄'].mean(),data[data['中风']=='否']['年龄'].mean()],'平均血糖':[data[data['中风']=='是']['平均血糖'].mean(),data[data['中风']=='否']['平均血糖'].mean()],'平均BMI':[data[data['中风']=='是']['体重指数'].mean(),data[data['中风']=='否']['体重指数'].mean()]})print(stroke_compare)# 可视化对比fig,axes=plt.subplots(1,3,figsize=(15,5))sns.barplot(x='中风',y='平均年龄',data=stroke_compare,ax=axes[0])axes[0].set_title('中风与非中风人群平均年龄对比')sns.barplot(x='中风',y='平均血糖',data=stroke_compare,ax=axes[1])axes[1].set_title('中风与非中风人群平均血糖对比')sns.barplot(x='中风',y='平均BMI',data=stroke_compare,ax=axes[2])axes[2].set_title('中风与非中风人群平均BMI对比')plt.tight_layout()plt.show()中风 平均年龄 平均血糖 平均BMI 0 是 67.712919 134.571388 30.471292 1 否 NaN NaN NaN# 3. 高血压与平均血糖的交叉分析# 将血糖分箱data['血糖水平']=pd.cut(data['平均血糖'],bins=[0,100,126,300],labels=['正常','偏高','糖尿病'])# 统计不同血压和血糖水平下的中风人数cross=pd.crosstab([data['高血压'],data['血糖水平']],data['中风'])print(cross)# 可视化交叉热力图cross_pct=cross.div(cross.sum(axis=1),axis=0)sns.heatmap(cross_pct,annot=True,fmt='.1%',cmap='Reds')plt.title('高血压与血糖水平的中风占比热力图')plt.show()中风 是 高血压 血糖水平 否 正常 69 偏高 24 糖尿病 56 是 正常 24 偏高 5 糖尿病 31三、最终项目结论
- 核心发现
(1)年龄是中风的首要风险因素:中风风险随年龄增长显著升高,60-80 岁是最高发年龄段,40 岁以上人群需重点预防。
(2)代谢指标存在协同效应:平均血糖与体重指数呈中等正相关,二者叠加会增加中风风险。
(3)生活方式与职业存在关联:私人 / 私营企业工作者、已婚人群的中风病例占比更高,提示压力、作息等因素的潜在影响。
- 建设性建议
(1)重点人群干预:对 40 岁以上、尤其是 60-80 岁的人群,应定期进行脑血管、血糖、血脂筛查,做到早发现、早干预。
(2)代谢综合管理:针对高血糖人群,建议同时控制体重,通过饮食调整和规律运动,降低血糖和 BMI 水平,减少中风风险。
(3)职业与生活方式指导:针对私人 / 私营企业工作者,建议关注工作压力管理,避免长期熬夜、久坐,保持健康的生活习惯。
(4)戒烟与健康宣教:即使是 “以前吸烟” 的人群,仍需持续关注血管健康,定期体检,降低中风复发风险。