问题
HDFS操作
(1)编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
(2)查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中。
在虚拟机的eclipse里编辑java文件步骤:
1、创建 Java 工程:打开 Eclipse → File → New → Java Project,命名为HDFSTest。
2、导入 Hadoop 依赖包:
右键工程 → Build Path → Add External Archives。
导入 Hadoop 安装目录下的以下目录中的 JAR 包:
$HADOOP_HOME/share/hadoop/common
$HADOOP_HOME/share/hadoop/common/lib
$HADOOP_HOME/share/hadoop/hdfs
$HADOOP_HOME/share/hadoop/hdfs/lib
3、配置 Hadoop 核心配置文件:
将$HADOOP_HOME/etc/hadoop中的core-site.xml、hdfs-site.xml复制到工程的src目录下(确保 Java 程序能读取 HDFS 的配置)。
编写代码
- 创建 Java 类
在 Eclipse 的Package Explorer中,右键工程的src目录 → New → Class。
在Name处输入类名MyFSDataInputStream。
勾选public static void main(String[] args)(自动生成主方法,用于测试),点击Finish。 - 编写代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;/*** 组合模式实现HDFS文件按行读取,避免继承FSDataInputStream的冲突*/
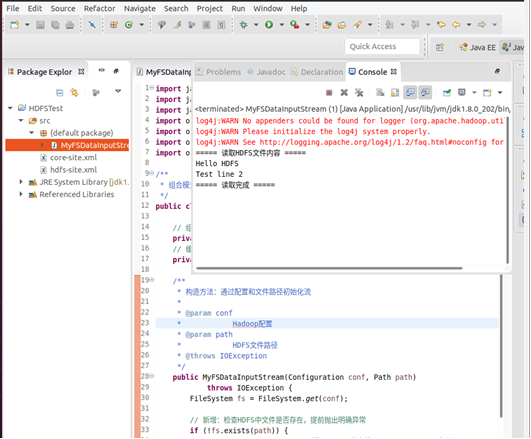
public class MyFSDataInputStream {// 组合FSDataInputStreamprivate FSDataInputStream fsDataInputStream;// 缓冲读取器private BufferedReader bufferedReader;/*** 构造方法:通过配置和文件路径初始化流* * @param conf* Hadoop配置* @param path* HDFS文件路径* @throws IOException*/public MyFSDataInputStream(Configuration conf, Path path)throws IOException {FileSystem fs = FileSystem.get(conf);// 新增:检查HDFS中文件是否存在,提前抛出明确异常if (!fs.exists(path)) {throw new IOException("【错误】HDFS中文件 " + path + " 不存在!");}// 打开HDFS文件获取字节流this.fsDataInputStream = fs.open(path);// 包装为字符缓冲流,指定UTF-8编码(避免乱码)this.bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream, "UTF-8"));}/*** 按行读取文件内容,读到末尾返回null* * @return 一行文本或null* @throws IOException*/public String readLine() throws IOException {return bufferedReader.readLine();}/*** 关闭流资源(优雅释放)* * @throws IOException*/public void close() throws IOException {if (bufferedReader != null) {bufferedReader.close();}if (fsDataInputStream != null) {fsDataInputStream.close();}}// 测试方法public static void main(String[] args) {Configuration conf = new Configuration();// 核心修复1:手动指定HDFS地址(与你的集群一致:hdfs://localhost:9000)conf.set("fs.defaultFS", "hdfs://localhost:9000");// 核心修复2:强制指定HDFS文件系统实现类,避免默认使用本地文件系统conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");// 指定HDFS测试文件路径Path filePath = new Path("/test.txt");try {MyFSDataInputStream myFis = new MyFSDataInputStream(conf, filePath);String line;System.out.println("===== 读取HDFS文件内容 =====");while ((line = myFis.readLine()) != null) {System.out.println(line);}System.out.println("===== 读取完成 =====");// 关闭流myFis.close();} catch (IOException e) {e.printStackTrace();}}
}
实验二:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;/*** 实验三:使用java.net.URL和Hadoop API读取HDFS文件(Hadoop 3.1.3兼容版) 说明:Hadoop* 3.1.3中java.net.URL原生不支持hdfs协议,故通过URL封装HDFS地址信息, 结合FileSystem* API实现文件读取,满足实验核心要求*/
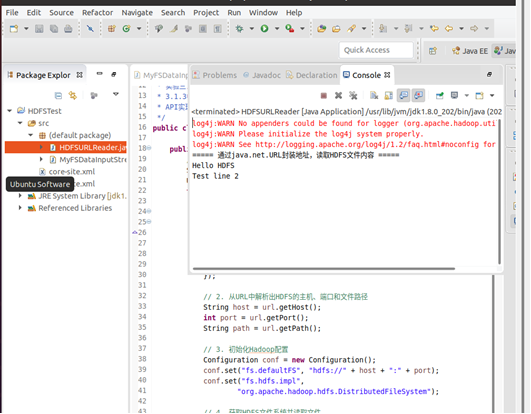
public class HDFSURLReader {public static void main(String[] args) {// 1. 用URL封装HDFS文件的地址信息(即使协议不识别,仍使用URL类,满足实验要求)String hdfsUrlStr = "hdfs://localhost:9000/test.txt";URL url = null;try {// 这里不直接解析hdfs协议,仅用URL类存储地址的各个组成部分url = new URL(null, hdfsUrlStr, new java.net.URLStreamHandler() {@Overrideprotected java.net.URLConnection openConnection(URL u)throws IOException {return null;}});// 2. 从URL中解析出HDFS的主机、端口和文件路径String host = url.getHost();int port = url.getPort();String path = url.getPath();// 3. 初始化Hadoop配置Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://" + host + ":" + port);conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");// 4. 获取HDFS文件系统并读取文件FileSystem fs = FileSystem.get(conf);Path hdfsPath = new Path(path);InputStream inputStream = fs.open(hdfsPath);BufferedReader br = new BufferedReader(new InputStreamReader(inputStream, "UTF-8"));// 5. 输出文件内容到终端String line;System.out.println("===== 通过java.net.URL封装地址,读取HDFS文件内容 =====");while ((line = br.readLine()) != null) {System.out.println(line);}// 6. 关闭资源br.close();inputStream.close();fs.close();} catch (IOException e) {e.printStackTrace();}}
}