(1). 因为PC=PC+2,所以没有跳转的时候,PC的增量是两个单位;每条指令占2个字节,所以PC的增量应该是两个字节,所以一个单位的长度是一个字节
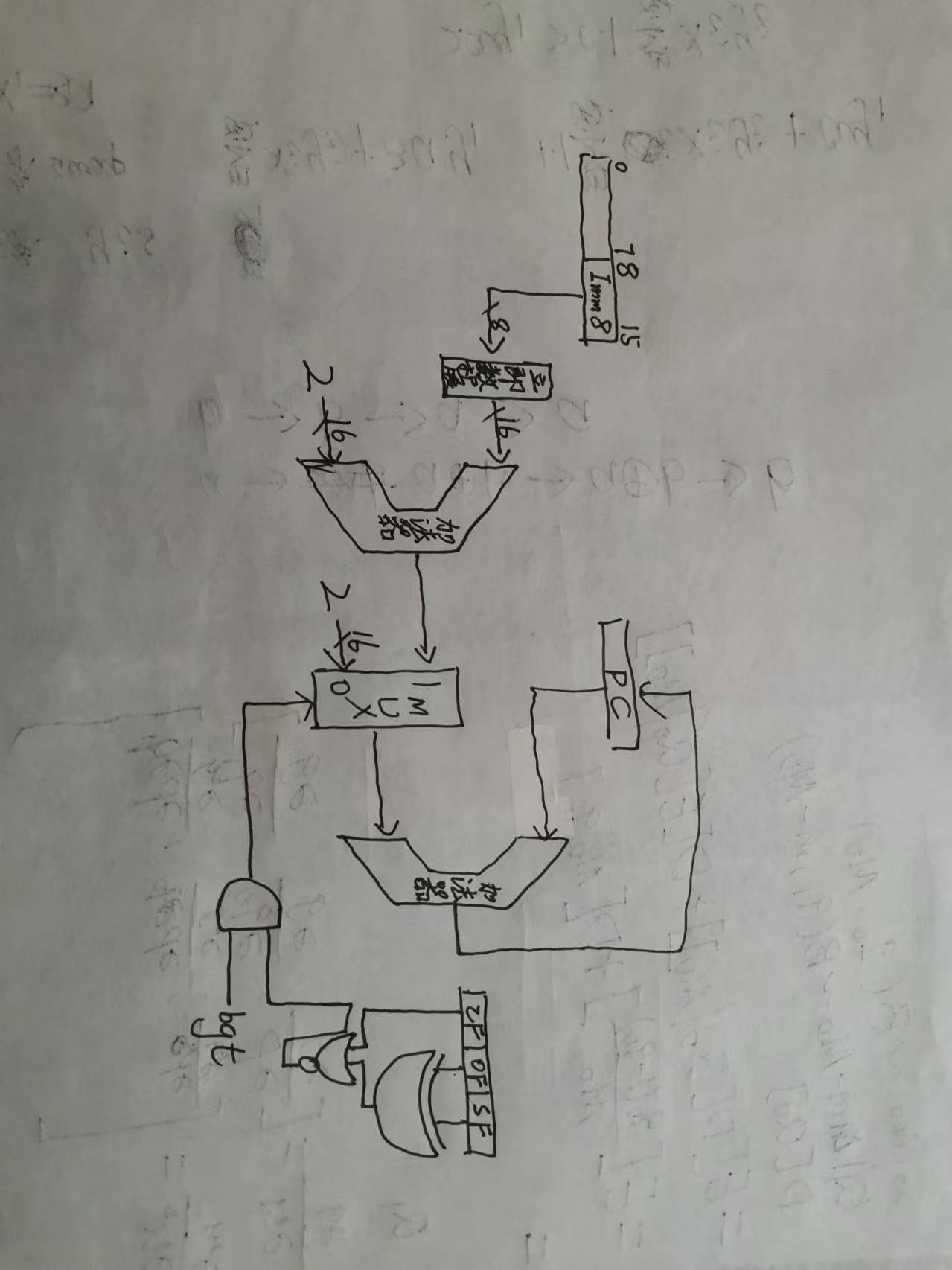
(2). 数据通路如下
- 若
RegWr=0,那么所有需写结果到寄存器的指令都不能正确执行 - 若
ALUASrc=0,则jal可能不能正确执行,比如当指令中的目标寄存器rd不是x0时,需要将PC+4存入rd中,但由于ALUASrc=0,PC不能作为ALU的输入,因而会执行错误 - 若
Branch=0,则B型指令可能出错 - 若
Jump=0,则J型指令出错 - 若
MemWr=0,则store类指令出错 - 若
MemtoReg=0,则load类指令出错
-
若
RegWr = 1,则所有不需要写结果到寄存器的指令不能正确执行 -
若
ALUASrc = 1,则所有需要寄存器值作为 ALU A 输入源的指令不能正确执行,因为 ALU 的 A 输入端始终来自 PC 而不是寄存器文件 -
若
Branch = 1:所有非 branch 类指令可能不能正确执行 -
若
Jump = 1:所有非 jump 类指令)不能正确执行 -
若
MemWr = 1:所有非 store 类指令不能正确执行 -
若
MemtoReg = 1:所有需要写寄存器但非 load 类指令不能正确执行
(1). 高级语言程序:
a = a ^ b;
b = a ^ b;
a = a ^ b;
于是可得指令如下:
xor rs, rs, rt
xor rt, rs, rt
xor rs, rs, rt
(2). 假设是单周期CPU,所以所有指令的执行时间相同。设swap指令的比例是\(x\),于是:
- 采用软件:\(3x+(1-x)=2x+1\)
- 采用硬件:\(1.1(x+(1-x))=1.1\)
于是当\(1.1<2x+1\),即\(x>0.05\)的时候,用硬件更好
(3).
- 对于单周期CPU,由于一个周期只可以写一次寄存器,所以不行
- 对于多周期CPU,由于一个周期可以写多次寄存器,所以可以
(1). 不能,瓶颈是存储单元的200ps,缩小非瓶颈的执行时间没有意义
(2). 不能,此时ALU操作时间为180ps,仍然不是瓶颈
(3). 此时ALU的操作时间是210ps,变成了瓶颈,会让流水线的执行速度降低
假设插入的流水线寄存器的个数定了并且各个阶段的执行时间确定,那么划分出来的各个阶段越均匀是越好的,于是可以得出下面的结果:
(1). 插入到C和D之间最均匀,此时最长的功能段执行时间为170ps,加上流水线寄存器的20ps,得到190ps;所以指令吞吐率为\(\frac{1s}{190ps}=5.26G\)条指令,指令执行时间为\(2\times 190ps=380ps\)
(2). 插入到B和C,D和E之间最均匀,此时最长的功能段执行时间为110ps,加上流水线寄存器的20ps,得到130ps;所以指令吞吐率为\(\frac{1s}{130ps}=7.69G\)条指令,指令执行时间为\(3\times 130ps=390ps\)
(3). 插入到A和B,C和D,D和E之间最均匀,此时最长的功能段执行时间为90ps,加上流水线寄存器的20ps,得到110ps;所以指令吞吐率为\(\frac{1s}{110ps}=9.09G\)条指令,指令执行时间为\(4\times 110ps=440ps\)
(4). 插入到A和B、B和C、C和D、D和E之间可以让吞吐率最大,此时最长的功能段执行时间为80ps,加上流水线寄存器的20ps,得到100ps;所以指令吞吐率为\(\frac{1s}{100ps}=10G\)条指令,指令执行时间为\(5\times 100ps=500ps\)
下面假设是单周期CPU
(1). 第1和第2条、第2和第3条、第2条和第4条、第3条和第4条指令之间有数据相关
(2). 需要插入3条nop,因为读寄存器是第二阶段,写寄存器是第五阶段,相差三个阶段
(3). 前面三条指令的数据冒险可以通过转发解决,但是还需要在lw和add之间插入一条nop
第1和第2条、第6和第7条指令之间有数据冒险,将与第2和第3条指令无关的第4条指令插入第2条指令之前,将与第6和第7条无关的第5条指令移动到第6条指令之后,如下:
lw s2, 100(s6)
add s6, s4, s7
add s2, s2, s3
lw s3, 200(s7)
lw s2, 300(s8)
sub s3, s4, s6
beq s2, s8, Loop
(1). 第4条和第5条指令之间有冒险,跳转指令(第五条bne指令)被阻塞一个时钟
(2). 第六条add指令会被阻塞1个周期;第七条无条件跳转指令会被阻塞,若其指令更新阶段在EX执行那么要阻塞两个周期否则只需要阻塞一个周期