
Hive是基于HDFS之上的数据仓库,它把所有的数据存储在HDFS中,Hive并没有专门的数据存储格式。当在Hive中创建了表,可以使用load语句将本地或者HDFS上的数据加载到表中,从而使用SQL语句进行分析和处理。
Hive的数据模型主要是指Hive的表结构,可以分为:内部表、外部表、分区表、临时表和桶表,同时Hive也支持视图。
 |
|---|
| 点击这里查看视频讲解:【赵渝强老师】Hive的数据模型 |
| |
一、使用Hive的内部表
内部表与关系型数据库中的表是一样的。使用create table语句可以创建内部表,并且每张表在HDFS上都会对应一个目录。这个目录将默认创建在HDFS的/user/hive/warehouse下。除外部表外,表中如果存在数据,数据所对应的数据文件也将存储在这个目录下。删除内部表的时候,表的元信息和数据都将被删除。
|
|---|
| 点击这里查看视频讲解:【赵渝强老师】Hive的内部表 |
下面使用之前的员工数据(emp.csv)来创建内部表。
(1)执行create table语句创建表结构。
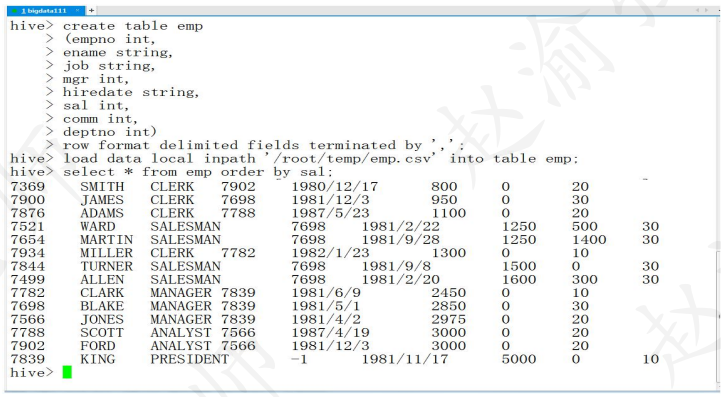
hive> create table emp
(empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
deptno int)
row format delimited fields terminated by ',';
由于csv文件是采样逗号进行分隔的,因此在创建表的时候需要指定分隔符是逗号。Hive表的默认分隔符是一个不可见字符。
(2)使用load语句加载本地的数据文件。
hive> load data local inpath '/root/temp/emp.csv' into table emp;
(3)使用下面的语句加载HDFS的数据文件。
hive> load data inpath '/scott/emp.csv' into table emp;
(4)执行SQL的查询。
hive> select * from emp order by sal;
(5)整个执行的过程如下图所示。
(6)查看HDFS的/user/hive/warehouse/目录可以看到创建的emp表和加载的emp.csv文件,如下图所示。

二、使用外部表
与内部表不同的是,外部表可以将数据存在HDFS的任意目录下。可以把外部表理解成是一个快捷方式,它的本质是建立一个指向HDFS上已有数据的链接,在创建表的同时会加重数据。而当删除外部表的时候,只会删除这个链接和对应的元信息,实际的数据不会从HDFS上删除。
|
|---|
| 点击这里查看视频讲解:【赵渝强老师】Hive的外部表 |
下面通过具体的步骤演示如何创建Hive的外部表。
[root@bigdata111 ~]# more students01.txt
1,Tom,23
2,Mary,22
[root@bigdata111 ~]# more students02.txt
3,Mike,24
(2)将数据文件上传到HDFS的任意目录。
hdfs dfs -mkdir /students
hdfs dfs -put students0*.txt /students
(3)在Hive中创建外部表。
hive> create external table ext_students
(sid int,sname string,age int)
row format delimited fields terminated by ','
location '/students';
(4)执行SQL的查询。
hive> select * from ext_students;
(5)执行的结果如下图所示。
