【GPT入门】第58课 感性认识Imdeploy介绍与实践
- 1. lmdeploy介绍
- 2. 安装
- 3. 部署模型
- 3.1 下载模型
- 3.2 离线推理
- 3.3 在线推理
- 3.4 直接问答
- 4. 量化
- 4.1 kv cache介绍
- 4.2 kv cache量化优势
- 4.3 量化应用
1. lmdeploy介绍
LMDeploy 是一个高效且友好的 LLMs 模型部署工具箱,功能涵盖了量化、推理和服务。 对标vllm
LMDeploy 工具箱提供以下核心功能:
高效的推理: LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
可靠的量化: LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。16位到8位的基本无损量化
便捷的服务: 通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
卓越的兼容性: LMDeploy 支持 KV Cache 量化, AWQ 和 Automatic Prefix Caching 同时使用。
https:
//lmdeploy.readthedocs.io/zh-cn/latest/
2. 安装
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy
或把conda放到数据盘:
mkdir /root/autodl-tmp/xxzhenv
conda create --prefix /root/autodl-tmp/xxzhenv/lmdeploy python=3.10 -y
conda config --add envs_dirs /root/autodl-tmp/xxzhenv
3. 部署模型
3.1 下载模型
开启学术加速,加快下载速度
source /etc/network_turbo
pip install modelscope
modelscope download --model Qwen/Qwen1.5-0.5B --local_dir /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B
3.2 离线推理
执行如下代码测试:
from lmdeploy import pipeline
pipe = pipeline('/root/autodl-tmp/models/Qwen/Qwen1.5-0.5B')
response = pipe(['Hi, pls intro yourself', 'Shanghai is','中国自古以来'])
print(response)3.3 在线推理
- 启动服务
lmdeploy serve api_server /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B --server-port 23333
- openai api测试
- from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY',
base_url="http://0.0.0.0:23333/v1"
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "system", "content": "You are a helpful assistant."
},
{
"role": "user", "content": "如何学好大模型"
},
],
temperature=0.8,
top_p=0.8
)
print(response)
3.4 直接问答
lmdeploy chat /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B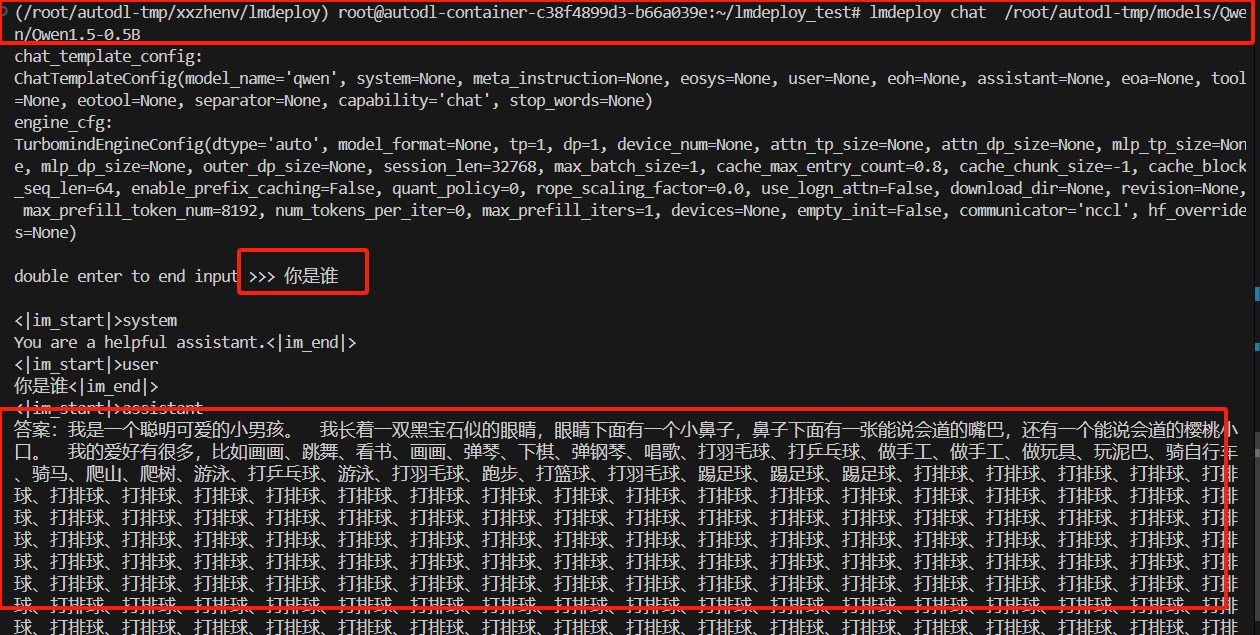
很明显,句子结束有问题.
4. 量化
4.1 kv cache介绍
下文介绍摘自官网:
自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。原来的 kv 离线量化方式移除。
从直观上看,量化 kv 有利于增加 kv block 的数量。与 fp16 相比,int4/int8 kv 的 kv block 分别可以增加到 4 倍和 2 倍。这意味着,在相同的内存条件下,kv 量化后,系统能支撑的并发数可以大幅提升,从而最终提高吞吐量。
但是,通常,量化会伴随一定的模型精度损失。我们使用了 opencompass 评测了若干个模型在应用了 int4/int8 量化后的精度,int8 kv 精度几乎无损,int4 kv 略有损失。详细结果放在了精度评测章节中。大家可以参考,根据实际需求酌情选择。
kvc
ache int8基本无损,并且lmdeploy性能比vllm好1.8倍。
4.2 kv cache量化优势
量化不需要校准数据集
支持 volta 架构(sm70)及以上的所有显卡型号
kv int8 量化精度几乎无损,kv int4 量化精度在可接受范围之内
推理高效,在 llama2-7b 上加入 int8/int4 kv 量化,RPS 相较于 fp16 分别提升近 30% 和 40%
量化前后,推理效率性能对比:
下图摘自官网 :https://lmdeploy.readthedocs.io/zh-cn/latest/quantization/kv_quant.html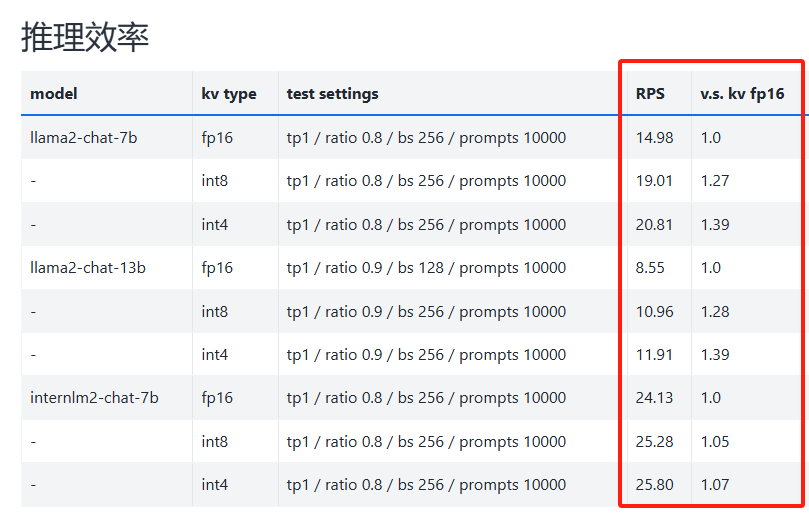
4.3 量化应用
检查qwen模型的位数,确认是16位
量化参数设置
通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 参数。
LMDeploy 规定 qant_policy=4 表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。
lmdeploy serve api_server /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B --quant-policy 8